
こんにちは。sinyです。
以前、以下の記事でスパースオートエンコーダモデルで時系列データの異常検知を試してみましたが、1入力、1出力という非常に単純なモデルでの検証でした。

今回は、応用編として多入力、多出力モデルで検証してみました。
検証内容
今回は以下の条件で異常検知の検証を行ってみました。
- 入力データは1サーバのCPU使用率、物理メモリ使用率の時系列データとする。
※データは10分間隔で取得したものを利用) - 異常検知は前回同様スパースオートエンコーダを利用する。
※2入力(CPU,メモリ)、2出力(CPU,メモリ)のオートエンコーダモデルを用いてみる。
検証に利用するデータは以下のような時系列データです。
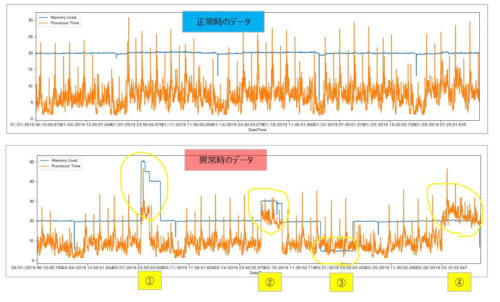
正常データ(上図)を用いて学習し、異常データ(下図)を投入した際に黄色丸でくくった部分(①~④)の異常状態を検知させることが目標です。
テストデータでは意図的に以下の4パターンの異常状態を作っています。
②CPU、メモリ使用率がともに上昇したケース
③メモリ使用率が通常状態とくらべて低くなったケース
④CPU使用率が上昇したケース
入力データの準備
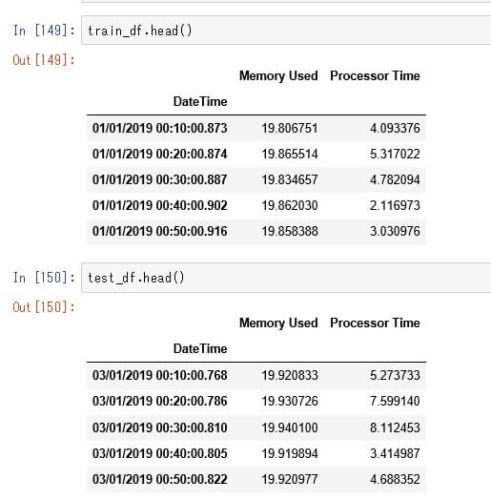
# cpuとメモリデータを各々抽出
train_cpu_df = pd.read_csv('train_data.csv', usecols=[2])
train_mem_df = pd.read_csv('train_data.csv', usecols=[1])
test_cpu_df = pd.read_csv('test_data.csv', usecols=[2])
test_mem_df = pd.read_csv('test_data.csv', usecols=[1])
※今回の例では各データの形状は(4386, 1)です。
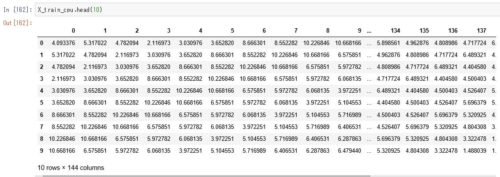
Windowサイズ毎の時系列入力データセットを生成します。
※Windowサイズは144(10分毎のデータなので24時間分)とします。
def subseq(x, w):
seq = np.zeros((len(x) - w + 1, w))
x_np = x.iloc[:, 0]
for i in range(len(x) - w + 1):
seq[i, :] = x_np[i:w+i]
return pd.DataFrame(seq)
w_size = 144 # ウィンドウサイズ
X_train_cpu = subseq(train_cpu_df, w_size)
X_test_cpu = subseq(test_cpu_df, w_size)
X_train_mem = subseq(train_mem_df, w_size)
X_test_mem = subseq(test_mem_df, w_size)
上記コードを実行すると以下のようにWindowサイズで分割した時系列データが生成されます。
sc = MinMaxScaler() X_train_cpu = sc.fit_transform(X_train_cpu) X_test_cpu = sc.fit_transform(X_test_cpu) X_train_mem = sc.fit_transform(X_train_mem) X_test_mem = sc.fit_transform(X_test_mem)
※今回の例ではデータの形状はそれぞれ(4243, 144)
以上で、入力データの準備は完了です。
モデル定義
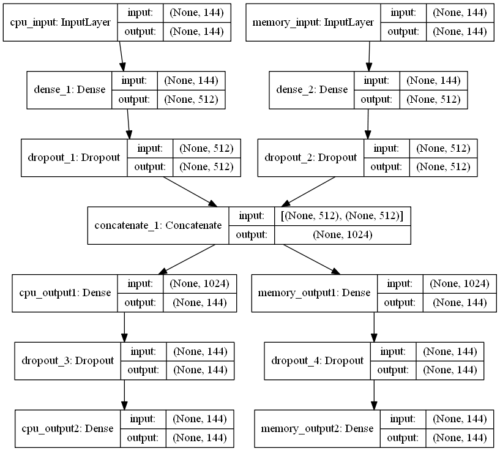
l1=10e-9 # L1正則化のパラメータ
enc_dim = 512 # 隠れ層のユニット数
cpu_input = Input(shape=(w_size,),name="cpu_input")
encoded_cpu = Dense(enc_dim, activation='relu',
activity_regularizer=regularizers.l1(l1))(cpu_input)
encoded_cpu = layers.Dropout(0.2)(encoded_cpu)
memory_input = Input(shape=(w_size,),name="memory_input")
encoded_memory = Dense(enc_dim, activation='relu',
activity_regularizer=regularizers.l1(l1))(memory_input)
encoded_memory = layers.Dropout(0.2)(encoded_memory)
concatenated = layers.concatenate([encoded_cpu , encoded_memory], axis=-1)
decoded_cpu = Dense(w_size, activation='relu',name="cpu_output1")(concatenated)
decoded_cpu = layers.Dropout(0.3)(decoded_cpu)
decoded_cpu = Dense(w_size, activation='relu',name="cpu_output2")(decoded_cpu)
decoded_memory = Dense(w_size, activation='relu',name="memory_output1")(concatenated)
decoded_memory = layers.Dropout(0.3)(decoded_memory)
decoded_memory = Dense(w_size, activation='relu',name="memory_output2")(decoded_memory)
autoencoder = Model([cpu_input, memory_input], [decoded_cpu, decoded_memory])
autoencoder.compile(optimizer='adadelta',
loss=['binary_crossentropy', 'binary_crossentropy'])
学習
2入力、2出力のオートエンコーダなので、入力データと教師データ部分にはそれぞれリスト形式で[X_train_cpu,X_train_mem]を指定します。
epochs = 100
history = autoencoder.fit([X_train_cpu,X_train_mem],
[X_train_cpu,X_train_mem],
epochs=epochs,
batch_size=None,
verbose=1)
学習結果の損失をプロットしてみます。
pd.DataFrame(history.history).plot()
history.historyからは全体の損失(loss)と2出力分(CPU、メモリ)の損失が返ってきます。
※以下は一番最初に1000エポック回してみた際のグラフです。
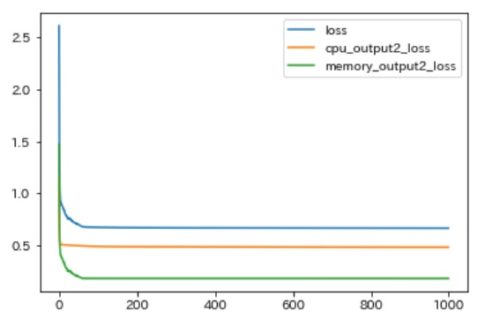
今回のケースでは、100エポック程度で収束したので最終的には100エポック指定で学習させました。
異常検知
テストデータを使って、トレーニング済みモデルで評価してみます。
decoded_cpu = pd.DataFrame(autoencoder.predict([X_test_cpu,X_test_mem])[0]) decoded_mem = pd.DataFrame(autoencoder.predict([X_test_cpu,X_test_mem])[1])
autoencoder.predict([X_test_cpu,X_test_mem] を実行すると出力はリスト形式で2つ(CPUとメモリ)返ってくるので、それぞれの返り値を取得してdecoded_cpuとdecoded_mem変数に一旦格納します。
※データの形状は(4243, 144)
入力したテスト用データ(X_test_cpu、X_test_mem)と、モデルの出力結果(decoded_cpu、decoded_mem)の二乗和の平方根を求めてプロットしてみます。(CPU,MEMORYについて各々求める)
dist_cpu = np.sqrt( np.sum( (decoded_cpu - X_test_cpu)**2, axis=1)) dist_cpu.plot(color="blue") dist_mem = np.sqrt( np.sum( (decoded_mem - X_test_mem)**2, axis=1)) dist_mem.plot(color="red")
各々の異常度をプロットすると以下のようになります。
赤がメモリ、青がCPU使用率の異常度です。
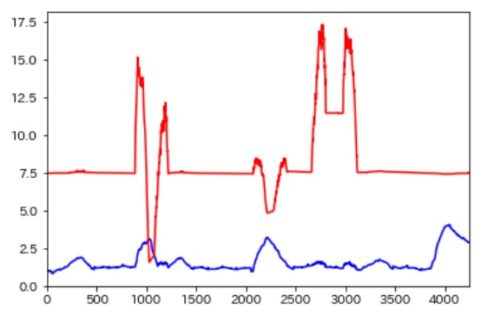
CPUとメモリで異常度の尺度が違うので、出力された異常度自体を正規化してみました。
dist_cpu_mean = dist_cpu.mean() dist_cpu_std = dist_cpu.std() dist_mem_mean = dist_mem.mean() dist_mem_std = dist_mem.std() dist_cpu = (dist_cpu - dist_cpu_mean) / dist_cpu_std dist_mem = (dist_mem - dist_mem_mean) / dist_mem_std dist_cpu.plot(color="blue") dist_mem.plot(color="red")
CPU、メモリの異常度の尺度が標準化されたのを確認。
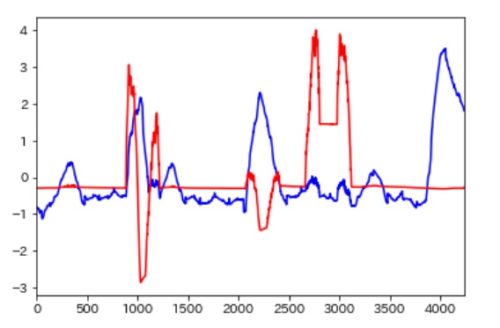
さらに、上記異常度(誤差)を合算してみます。
# 誤差の合算値 dist_total = (dist_cpu + dist_mem)*10 dist_total.plot()
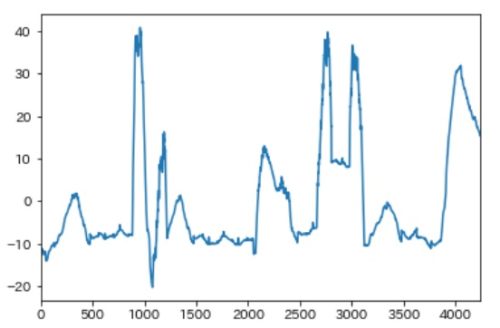
最後にテスト用のCPU、メモリ使用率グラフに異常度を合算した上記グラフを重ねると以下のようになりました。
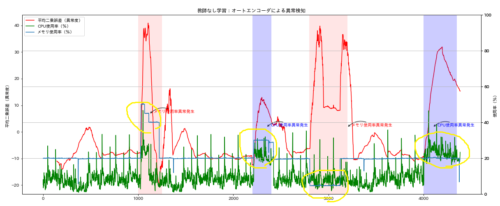
黄色で囲った以下の4つの異常パターンの部分で異常度(赤線)のグラフが上昇しているのが確認できました。
②CPU、メモリ使用率がともに上昇したケース
③メモリ使用率が通常状態とくらべて低くなったケース
④CPU使用率が上昇したケース
まとめ
まだまだディープラーニングは初心者レベルなので、これが正攻法のやり方なのかはわかりませんが、結果としては目標をある程度満たせるような学習モデルを構築することができました。
以下は、試行錯誤した際のまとめです。
- ディープラーニングを活用すると、単純な閾値による監視ではなく通常状態とは違う状態を異常として検知できるため、値が上振れしたケース(高負荷状態)のほか、下振れした場合(通常とは何か違う変化)も異常として検知できる。
- エポック数を回しすぎると異常検知がうまくいかないケースがあった。
- 正則化パラメータのチューニングはわりと重要。(精度に影響する)
- ちょっとネットワークを深くしてもたいして変わらない。
- Dropoutを入れないと異常を検知できない箇所があった。(例:メモリ使用率が上がってるのに異常度が下がってしまう)
- 複数出力の場合、出力によって異常度の尺度が違ってくるケースがあるので、そのまま異常度を合算すると特定データに引っ張られて意図した異常検知ができないケースが出てくる。
→算出した各異常度の値を標準正規化(0~1)した後に合算するとよい感じになった。 - 算出した各データの異常度に重み係数などを付加してあげれば「どのデータの異常を重視するか?」といった重要度の調整もできるのではないかと思う。












