こんにちは。sinyです。
この記事では、データ分析入門におすすめなpythonライブラリーを紹介します。
pandas_profiling
pandas_profilingというpythonライブラリーを使うとたったの4行のコードを実行するだけで以下の情報を分析することができます。
- データの概要
- データの特徴量に関する情報
- 相関関係(データフォーマットによっては表示されない)
- サンプルデータの表示
データの準備
この記事では、ITダッシュボードから各府省で利用されている情報システム情報を分析してみたいと思います。
ITダッシュボードとは、「各府省のIT投資の状況を、一貫性を持って、誰でも確認できるサイト」です。
pandas_profilingの利用方法
まずは、必要なモジュールをインストールします。
pip install pandas-profiling pip install jupyter
jupyter notebookコマンドでJupyterを起動します。
コード実行に必要なモジュールをインポートします。
import pandas as pd import pandas_profiling as pp
pandasのread_csvメソッドを使って先ほどダウンロードした府省で利用しているシステム情報のCSVファイルを読み込みます。
df = pd.read_csv('BasicInformationAll_20190512181203.csv',encoding='cp932')
以下のコードで分析結果のレポートを表示します。
pp.ProfileReport(df)
レポート結果が表示されます。
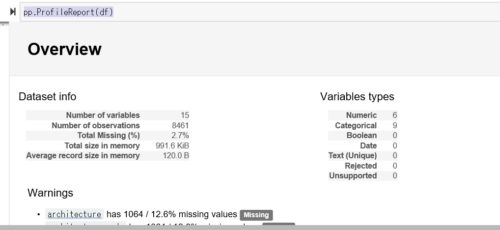
Jupyter Notebook上だと若干見にくいと思う方もいると思いますが、HTMLファイル形式でダウンロードすることもできます。
profile = pp.ProfileReport(df) profile.to_file(outputfile="output.html")
実際に分析結果を出力したHTMLファイルはこちら→ output.html
※動作確認したい方は右クリックから名前を付けて保存を選んでください)
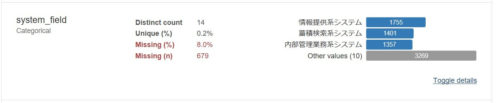
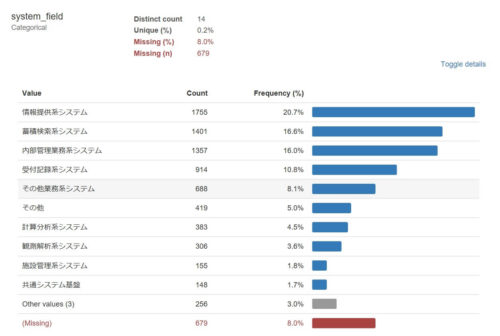
例えば、「system_filed」の部分を見ると以下のような分析結果が表示されています。
これは、各省庁でどんなシステムがいくつ存在しているかを表していますが、14項目のうちの4つしか表示されていません。
また、Missing項目が8%となっているので、欠損している項目データが結構あることがわかります。
まとめ
- pandas_profilingを利用すればたったの数行でデータの特性や、基本的な統計情報を可視化して確認することができます。
- html形式でダウンロードすれば他の人にも共有することができるので便利です。
pandas_profilingを利用してデータの分析結果をファイル出力するのはたったの数行でできてしまうので、DjangoといったWEBアプリケーションフレームワークに組み込むことで、「分析したいCSVファイルをWEBにアップロード→解析結果をファイル出力する」といったウェブアプリが、わりと簡単に実装できるのではないかと思っています。
近いうちにDjangoで実装してみたいと思っています。