【Django × ディープラーニング】AIアプリ開発完全ガイド|画像認識 Web サービスを Keras + Django で実装

目次
- 1 user@sinyblog:~/article ❯ 01_section_1.mdはじめに
- 2 user@sinyblog:~/article ❯ 02_ai_django.mdAI+Djangoを題材に選んだわけ
- 3 user@sinyblog:~/article ❯ 03_section_3.md環境について
- 4 user@sinyblog:~/article ❯ 04_web.mdWEBアプリ化するまでの全体の流れ
- 5 user@sinyblog:~/article ❯ 05_demo.mdDEMOアプリについて
- 6 user@sinyblog:~/article ❯ 06_section_6.md実装手順の説明
- 7 user@sinyblog:~/article ❯ 07_section_7.md参考にした書籍
- 8 user@sinyblog:~/article ❯ 08_section_8.mdまとめ
Django × Deep Learning · MNIST 手書き数字認識
機械学習モデルを「Web から使えるサービスとして公開したい」というニーズは、AI エンジニアにとって避けて通れない課題です。本記事では、ディープラーニングの入門題材として定番の MNIST(手書き数字認識)モデルを Django + Keras で Web アプリ化する完全手順 を解説します。ブラウザから画像をアップロード → Django ビューで Keras モデルが推論 → 結果を画面表示、という一連のフローをコード付き(動画付き)で構築します。本記事は Django Advent Calendar 2018 13 日目の記事を 2026 年版にリデザインしたものです。
user@sinyblog:~/article ❯ 01_section_1.mdはじめに
「お前だれよ?」という方が99.999%だと思いますので、簡単に自己紹介します。
- Python、Djangoは始めて1年未満(もうちょっとで1年)
- アプリ開発は初心者で、2018年になり趣味でプログラミングを始めた。
- 2018年にpyconJPを初めて見に行く。
- AIにも興味を持ち始め、此方も独学で勉強を始めて先月ディープラーニングのG検定を取得
- つい最近akiyokoさんの輪読会に初めて参加。
- 最近Django入門者向けのチュートリアル記事を作ってます。(一部公開済み)
2018年は私にとっては「Python,Djangoとの出会い」の年でした。
初めてプログラミングという世界に踏み出した年でもありました。
先日(12/15)Django Advent Calendarを覗いたところ12/13分が空いていたので、勢いで参加ボタンをポチってしまいました・・・
https://twitter.com/shinya_hd/status/1073828276135649280
あまり時間もなかったのですが、今できることから何が良いか考えた結果「AI+Django」で比較的簡単にできそうな題材を選んでみました。
user@sinyblog:~/article ❯ 02_ai_django.mdAI+Djangoを題材に選んだわけ
AIに興味を持ってディープラーニングの勉強に取り組んだ入門者ならよくわかると思うのですが、
入門書やセミナーなどでは必ずと言っていいほどMNISTの手書き数字画像認識がでてきてこんな感じで進んでいきます。
まずはデータセットを以下のような感じで読み込む。
※kerasの場合
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()※sklernの場合
from sklearn import datasets
digits = datasets.load_digits()何かよくわかんないけど、これ実行しておけば画像データがロードされて、訓練データとテストデータに分けてくれる模様(なんか便利!)
続いて学習モデルを定義して、モデルをコンパイルして、model.fit流すと学習が進んで、正解率とかLOSSの確率がでてきて、以下のようにグラフ化すると精度がだんだん上がって95%でいい感じになっていることが確認できた!
チュートリアルが終わった後、現実のケースに合わせて適用しようと思った場合に、「あれ、入力データってどうやって取り込むの?、ラベル付けってどこでやってたんだっけ?」みたいになるわけです。
で、大体MNISTを終わって次にCNNとかGANがでてきて、自然言語が出てくるともうおなか一杯になってくるわけです。(私も例外ではなく・・)
この時点でモチベーションが保てずに挫折してしまう人が多いんじゃないかなと思います。
幸い、2018年になってDjangoに手を出し始めていたので、MNISTをWEBアプリ化してとにかく見える形にしたらよいんじゃないかと考えました。
以下の記事でも少し触れていますが、見栄えはいったん置いておいて、兎に角、
「見える形にしてみる」という発想はビジネスにおいても非常に重要だと思います。

そんなわけで、よく知られているディープラーニングのチュートリアル(MNIST)を題材に少し手を加えた形で学習モデルを構築し、Djangoを使ってWEBアプリ化を実現するという題材にチャレンジしてみました。
user@sinyblog:~/article ❯ 03_section_3.md環境について
この記事の内容は、以下の環境で構築しました。
| 区分 | バージョン |
| OS | Windows10 |
| Python | 3.6(anacconda) |
| Django | 2.1.4 |
| Keras | 2.2.4 |
| Pillow | 5.3.0 |
| tensorflow | 1.12.0 |
| ブラウザ | Chrome |
※開発はローカル環境で開発サーバを起動して動作確認しています。
※python,Django,AIの専門家ではないのでコーディングがきれいじゃないとか、変なバグあるかもしれません。
user@sinyblog:~/article ❯ 04_web.mdWEBアプリ化するまでの全体の流れ
兎にも角にも、初学者にとってはまずはイメージするのが大事だと思ったので、今回作成した画像認識アプリの簡単な解説動画を作りましたのでご覧ください。
(突貫で作った動画なので見ずらい点はご了承ください・・)
こんな感じで自分が勉強している成果を見える形にできると、モチベーションが上がって
挫折しづらくなると思うんですよね。
さて、WEBアプリ化までの全体の流れを説明します。
②必要なモジュールのインストール(pipコマンド)
※そもそもPython環境がない方は以下の記事等を参考に導入してください。

③Django初期設定
※プロジェクト、アプリケーション、言語設定、管理者権限ユーザ作成、
ぐらいまで。
④学習モデルの定義と学習の実行
※学習結果をファイルに保存しておく。
⑤Djangoのビュー(views.py)の作成
※④で作成したモデルを利用する。
⑥URLパターン(urls.py)の設定
⑦テンプレートの作成(htmlファイル)
やることは以上です。
また、今回のアプリの動作、仕様は以下の通りです。
あと、普通のMNISTチュートリアルだと28x28サイズ固定ですが、この記事では学習時にちょっとだけ違うサイズの画像を与えることで、多少サイズが違う入力画像を与えた場合もそれなりに言い当ててくれる学習モデルを目指して作っていきたいと思います。
user@sinyblog:~/article ❯ 05_demo.mdDEMOアプリについて
実際に動かせるデモアプリ(Djangoプロジェクト)を作りました。
https://github.com/sinjorjob/django-mnist
※ReadMeの手順に従ってセットアップしてください。
※アプリを動作させるところまでは簡単に実装できるようになっています。
入門者の方は、実際に動かしてみるところから始めるとモチベーションが上がってよいと思いますので、ぜひチャレンジしてみてください!
user@sinyblog:~/article ❯ 06_section_6.md実装手順の説明
実際にAIアプリを実装していくときにこんなことをしなくてはいけないんだろうな~ということをイメージしながら作ってみたので、最初からかなり面倒くさいことしてます!
(実務でAIやったことないので細かい部分はわかりませんが・・)
では1つずつ説明していきます。
①MNISTデータセットのダウンロード
データのダウンロードは書籍によく出てくるようなコマンド1発ではなく、
実際にデータセットのファイルをダウンロードして準備します。
データセットは「google dataset search」からダウンロードします。
上記リンクにアクセス後、「mnist」で検索→画面左側の「MNIST as .jpg」を選択後に画面右側のKaggleボタンを押す→Download ALLの順でデータセットファイルをダウンロードします。

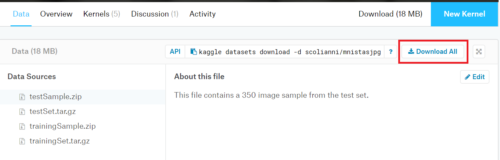
ダウンロードしたmnistasjpg.zipを解凍して手書き数字画像データをフォルダに配置していきます。
解凍すると以下の2つのフォルダ内にデータファイル(JPG)が入っています。
trainingSampleフォルダ(600ファイル)
testSample(350ファイル)
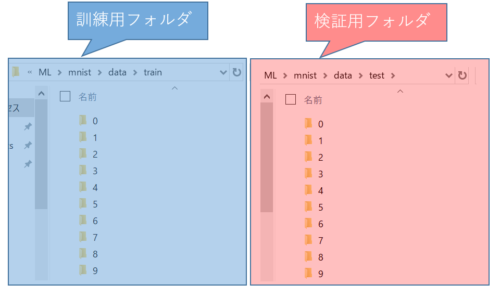
今回は、以下のような感じでtrainingSampleフォルダ内のファイルは訓練用フォルダに、
testSampleフォルダ内のファイルは検証用フォルダへ画像に描かれている数字毎にフォルダ(0~9)を作成してデータを格納していきます。
(data\train\0配下には数字0のデータだけ、data\train\1配下には数字1のデータだけ入れるという感じです)
C:\django\ML\mnist\data\test\1~9のフォルダを作る → 検証用データを入れる
以下のような感じです。
なんでこんな面倒くさいことやるのか?というと、きっと実務でも最初にこうしたデータセットの準備、ラベル付けといった面倒くさくて泥臭い作業があって大変なんだろうなと思ったのでやってみました。
データの前処理を行うツールなどもあるようですが、結局は人手でこうしたラベル付け等の作業を行う必要があるのかなと思います。
今回は1データファイルずつ目視で数字を確認して数字毎のフォルダに振り分けしました。
(これが一番大変だったかもしれない・・)
あと、目で見てもよくわからない画像がいくつかあったのでそれらは除外しちゃいました。
(実はこういう作業も結構大事だったりするのかな?)
MNISTのデータは28x28ピクセルと固定サイズで決め打ちされているので、普通に学習させるとそれ以外の画像サイズを入力に与えると、ことごとく誤判定になるのですが、それじゃちょっとつまらない!
ということで、多少サイズが違う入力画像を与えた場合もそれなりに言い当ててくれる学習モデルになることを狙って、28x28以外のサイズの0~9の数字を書いた自作の画像を20枚ほど作成して訓練データに紛れ込ませてみました。
さて、目視でフォルダに振り分けたデータは最終的に以下のようになりました。
(フォルダ毎の数もいちお確認)
====================================================
total training images: 610
====================================================
total training 0 images: 60
total training 1 images: 63
total training 2 images: 62
total training 3 images: 62
total training 4 images: 63
total training 5 images: 59
total training 6 images: 61
total training 7 images: 55
total training 8 images: 63
total training 9 images: 62
====================================================
total validation images: 340
====================================================
total validation 0 images: 42
total validation 1 images: 37
total validation 2 images: 29
total validation 3 images: 46
total validation 4 images: 34
total validation 5 images: 30
total validation 6 images: 31
total validation 7 images: 31
total validation 8 images: 30
total validation 9 images: 30 ファイルの合計数は、後々のことを考えて一の位が0になる数に微調整しました。
こんな感じで、訓練(train)、検証用(test)フォルダ毎&数字(0~9)毎にフォルダを掘って画像を分けておくと、あとでKeras君がフォルダ名を見て勝手にデータファイルに対してラベル付けを行ってくれます。
以上で、データの下準備は完了です。
②必要なモジュールのインストール(pipコマンド)
ここは簡単で、以下のモジュールをpipでインストールするだけです。
| 区分 | コマンド |
| Django | pip install django |
| Keras | pip install keras |
| Pillow | pip install pillow |
| tensorflow | pip install tensorflow |
③Django初期設定
ここも簡単なので、実行コマンドだけ記載しておきます。
(プロジェクト名=tutorial)
・言語設定(英語→日本語)
・DBはデフォルト(Sqlite)
・アプリケーション作成(python manage.py startapp mnist)
・python manage.py runserverでWEBにアクセスできることを確認。
・settings.pyのINSTALLED_APPSにbootstrapform、mnistを追加しておく。
・マイグレーション
python manage.py makemigrations mnist
python manage.py migrate
・管理者ユーザ作成(python manage.py createsuperuser)
※ちなみに今回モデル(models.py)の設定は不要です。
以上でDjango初期設定は完了です。
④学習モデルの定義と学習の実行
Kerasを使ってモデリングと学習を行います。
今回、私はwin10 PC(GPU搭載なし)でjupyter notebookでコーディングと学習を実施しましたが、数分で学習できましたのでGPUは不要です。
まずは、こんな感じ(コード汚いですが・・・)で訓練と検証用フォルダ内のデータ数を確認しておきます。
訓練用が610ファイル、検証用が340ファイルあります。
import os
#baseディレクトリ
base_dir = 'C:\\django\\ML\\mnist\data'
#訓練ディレクトリ
train_dir = os.path.join(base_dir, 'train')
#テストディレクトリ
validation_dir = os.path.join(base_dir, 'test')
#訓練ディレクトリ配下の数字1~9の画像のディレクトリ
train_0_dir = os.path.join(train_dir, '0')
train_1_dir = os.path.join(train_dir, '1')
train_2_dir = os.path.join(train_dir, '2')
train_3_dir = os.path.join(train_dir, '3')
train_4_dir = os.path.join(train_dir, '4')
train_5_dir = os.path.join(train_dir, '5')
train_6_dir = os.path.join(train_dir, '6')
train_7_dir = os.path.join(train_dir, '7')
train_8_dir = os.path.join(train_dir, '8')
train_9_dir = os.path.join(train_dir, '9')
#訓練データの合計ファイル数
total_train_images = 0
total_train_images+= len(os.listdir(train_0_dir))
total_train_images+= len(os.listdir(train_1_dir))
total_train_images+= len(os.listdir(train_2_dir))
total_train_images+= len(os.listdir(train_3_dir))
total_train_images+= len(os.listdir(train_4_dir))
total_train_images+= len(os.listdir(train_5_dir))
total_train_images+= len(os.listdir(train_6_dir))
total_train_images+= len(os.listdir(train_7_dir))
total_train_images+= len(os.listdir(train_8_dir))
total_train_images+= len(os.listdir(train_9_dir))
print("====================================================")
print("total training images:", total_train_images)
num_train_images = total_train_images
print("====================================================")
#各数字毎のファイル数
print("total training 0 images:", len(os.listdir(train_0_dir)))
print("total training 1 images:", len(os.listdir(train_1_dir)))
print("total training 2 images:", len(os.listdir(train_2_dir)))
print("total training 3 images:", len(os.listdir(train_3_dir)))
print("total training 4 images:", len(os.listdir(train_4_dir)))
print("total training 5 images:", len(os.listdir(train_5_dir)))
print("total training 6 images:", len(os.listdir(train_6_dir)))
print("total training 7 images:", len(os.listdir(train_7_dir)))
print("total training 8 images:", len(os.listdir(train_8_dir)))
print("total training 9 images:", len(os.listdir(train_9_dir)))
#検証ディレクトリ配下の数字1~9の画像のディレクトリ
validation_0_dir = os.path.join(validation_dir, '0')
validation_1_dir = os.path.join(validation_dir, '1')
validation_2_dir = os.path.join(validation_dir, '2')
validation_3_dir = os.path.join(validation_dir, '3')
validation_4_dir = os.path.join(validation_dir, '4')
validation_5_dir = os.path.join(validation_dir, '5')
validation_6_dir = os.path.join(validation_dir, '6')
validation_7_dir = os.path.join(validation_dir, '7')
validation_8_dir = os.path.join(validation_dir, '8')
validation_9_dir = os.path.join(validation_dir, '9')
#検証データの合計ファイル数
total_validation_images = 0
total_validation_images+= len(os.listdir(validation_0_dir))
total_validation_images+= len(os.listdir(validation_1_dir))
total_validation_images+= len(os.listdir(validation_2_dir))
total_validation_images+= len(os.listdir(validation_3_dir))
total_validation_images+= len(os.listdir(validation_4_dir))
total_validation_images+= len(os.listdir(validation_5_dir))
total_validation_images+= len(os.listdir(validation_6_dir))
total_validation_images+= len(os.listdir(validation_7_dir))
total_validation_images+= len(os.listdir(validation_8_dir))
total_validation_images+= len(os.listdir(validation_9_dir))
print("====================================================")
print("total validation images:", total_validation_images)
num_test_images = total_validation_images
print("====================================================")
print("total validation 0 images:", len(os.listdir(validation_0_dir)))
print("total validation 1 images:", len(os.listdir(validation_1_dir)))
print("total validation 2 images:", len(os.listdir(validation_2_dir)))
print("total validation 3 images:", len(os.listdir(validation_3_dir)))
print("total validation 4 images:", len(os.listdir(validation_4_dir)))
print("total validation 5 images:", len(os.listdir(validation_5_dir)))
print("total validation 6 images:", len(os.listdir(validation_6_dir)))
print("total validation 7 images:", len(os.listdir(validation_7_dir)))
print("total validation 8 images:", len(os.listdir(validation_8_dir)))
print("total validation 9 images:", len(os.listdir(validation_9_dir)))
====================================================
total training images: 610
====================================================
total training 0 images: 60
total training 1 images: 63
total training 2 images: 62
total training 3 images: 62
total training 4 images: 63
total training 5 images: 59
total training 6 images: 61
total training 7 images: 55
total training 8 images: 63
total training 9 images: 62
====================================================
total validation images: 340
====================================================
total validation 0 images: 42
total validation 1 images: 37
total validation 2 images: 29
total validation 3 images: 46
total validation 4 images: 34
total validation 5 images: 30
total validation 6 images: 31
total validation 7 images: 31
total validation 8 images: 30
total validation 9 images: 30続いて学習モデルを定義します。
今回は、以下のような基本的なCNNモデルを定義します。
◆入力データ:28x28x1(28x28ピクセルのグレースケール)
◆畳み込み→MaxPooling→畳み込み→MaxPooling→畳み込み→平坦化→出力
◆出力は数字の0~9なのでDenseは10です。
◆出力層はSoftmax,それ以外はRelu
#学習鵜モデルの定義
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))補足ですが、入力データの形状はグレースケールの場合は、(28x28x1)、カラーの場合は(28x28x3)になります。
もし、上記の入力形状が何言ってるかよくわからないという方は、以下の記事を参考にスカラー、ベクトル、テンソルについてまず理解することをお勧めします。

さて、先ほど定義したCNNモデルのmodel.summary()の結果はこんな感じです。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_52 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_36 (MaxPooling (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_53 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_37 (MaxPooling (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_54 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
flatten_14 (Flatten) (None, 576) 0
_________________________________________________________________
dense_27 (Dense) (None, 64) 36928
_________________________________________________________________
dense_28 (Dense) (None, 10) 650
=================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
つづいて、モデルをコンパイルします。
多クラス単一ラベル分類なので損失関数にcategorical_crossentropy(最終層はsoftmax)を利用します。
from keras import optimizers
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
つづいて、Kerasの「ImageDataGenerator」という機能を使って、データの前処理やラベル付けをしていきます。
ImageDataGeneratorでは以下のようなこと実施してくれます。
以下のディレクトリからデータを読み込んで28x28にリサイズして形状が(20,28,28,1)のバッチデータと形状が(20,10)の10クラスのラベルを生成してくれます。
C:\django\ML\mnist\data\test
C:\django\ML\mnist\data\train
ImageDataGeneratorを使うとフォルダ名をデータのラベル名として自動で割り当ててくれます。
from keras.preprocessing.image import ImageDataGenerator
batch_size = 10
#以下のジェネレータは28x28のグレースケール画像からならるバッチ((20,28,28,1)と10クラスのラベル(形状は(20,10)を生成する。
#バッチごとに10のサンプルが存在する。
# 全イメージデータを1/255(0~1)にrescale
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
#ターゲットのディレクトリを指定(今回だとc\django\ML\data\trainフォルダ)
train_dir,
#すべての画像を28x28にリサイズする(アップロードするファイルサイズによらず28x28にするため)
target_size=(28, 28),
#グレースケール指定(今回はグレースケール画像なので。カラーなら'rgb'を指定する)
color_mode='grayscale',
#バッチサイズ
batch_size=batch_size,
# categorical_crossentropyをつかうので多クラス分類が必要。
class_mode='categorical')
#以下は上記 train_datagenと同じことをしているだけ。
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(28, 28),
color_mode='grayscale',
batch_size=batch_size,
class_mode='categorical')
Found 610 images belonging to 10 classes.
Found 340 images belonging to 10 classes.
ポイントは、
・どんなサイズのデータが来ても28x28ピクセル固定にしたい。
→target_size=(28, 28)を指定
・画像はグレースケール指定とする。
→color_mode='grayscale'を指定(カラーなら'rgb'を指定する)
・categorical_crossentropyをつかうので多クラス分類が必要。
→class_mode='categorical'を指定
・batch_size = 10
→訓練、検証データ数がそれぞれ610、340個なので、バッチサイズを10にして、
全訓練データサイズ/ バッチサイズ(610/10)が割り切れるようにしておく。
※検証データも同じ。
実際上記ジェネレータでどんなデータが出来上がっているかイメージしづらいので、
以下のコードで確認。
# Generatorの戻り値としては、以下のようにデータとラベルに関するデータが生成される。
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
print('indices:', train_generator.class_indices)
break
data batch shape: (10, 28, 28, 1)
labels batch shape: (10, 10)
indices: {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
train_generator(ジェネレータ)により、(10,28,28,1)のデータと、ラベルとして(10,10)のデータが生成されます。
わかりやすく言い換えると、データが「バッチサイズ、縦、横、グレースケール」
ラベルが「バッチサイズ分のラベル」です。
最初の「10」はバッチサイズが10なので、(10,28,28,1)
→28x28ピクセルでグレースケール(1)のデータが10セットずつ生成されているということです。
ラベル(10,10)は、0~9の10個が10セットで(10,10)ずつラベルデータが生成されているような感じです。
indicesには以下のような形式でラベルデータが保存されるので、この値を確認することで実際にラベル付けされた値を確認できます。
・辞書型のデータ
・{label:番号}で保存されている。
つまり、以下の例だとフォルダ名「0」にラベル「0」を割り当てる、
フォルダ名「1」にラベル「1」を割り当てる・・・・ということをしてくれています。
indices: {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
以上で学習の準備ができたので学習していきます。
#学習
history = model.fit_generator(
train_generator,
steps_per_epoch=num_train_images // batch_size,
epochs=100,
validation_data=validation_generator,
validation_steps=num_test_images // batch_size)
学習が終わったらモデルを保存しておきます。
#モデルの保存
model.save('mnist.h5')
念のためモデルのロードを確認します。
#モデルのロード
from keras.models import load_model
model = load_model('mnist.h5')
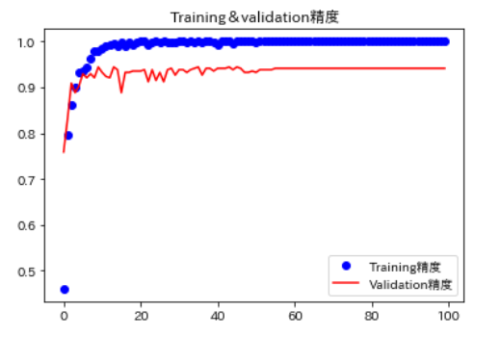
学習結果も可視化して確認しておきます。
import matplotlib.pyplot as plt
import japanize_matplotlib
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training精度')
plt.plot(epochs, val_acc, 'b', color="red",label='Validation精度')
plt.title('Training&validation精度')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training損失')
plt.plot(epochs, val_loss, 'b', color="red", label='Validation損失')
plt.title('Training&validation損失')
plt.xlabel('エポック数')
plt.legend()
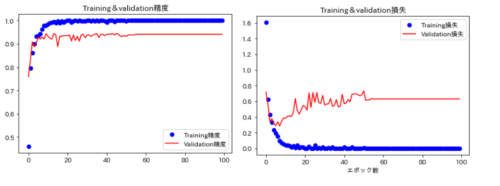
plt.show()今回はこんな感じの精度になりました。
新しいデータで試しに予測してみましょう。
# 新しいデータで予測
from PIL import Image
import numpy as np
img = Image.open("C:\\django\\ML\\mnist\\data\\pred\\test\\sample.jpg")
gray_img = img.convert('L')
img = gray_img.resize((28, 28))
img = np.array(img).reshape(1,28,28,1)
result = (model.predict(img, batch_size=None, verbose=0, steps=None)).argmax()
print(result)
8
上記のコードでは以下を実施しています。
①テスト用の画像ファイル「C:\django\ML\mnist\data\pred\test\sample.jpg」を読み込む。
②imgでOpenして、img.convert('L')でグレースケール化
③img.resizeでファイルサイズを28x28ピクセルにリサイズ
④reshapeで(1,28,28,1)次元に変換(定義したCNNモデルの入力形状に合わせるため)
⑤最後にpredictでimgを渡して、学習済みモデルを使って予測結果を受け取り、
argmax()で最大値のINDEXデータを取得しています。
※predictの結果は[0,0,0,0,0,0,0,0,1,0]のようなOne-Hot情報になっているので
argmaxで最大(=1)のINDEX番号を取得しています。
以上で、学習モデルの準備が完了しました。
この学習モデルをDjangoに組み込んでウェブアプリを作っていきます。
Djangoの開発
Django側で実施するのは以下の3つだけです。
②URLパターン(urls.py)の設定
③テンプレートの作成(htmlファイル)
まずビューの設定です。
導入部で必要なモジュールをImportしておきます。
from django.shortcuts import render, redirect
from PIL import Image
import numpy as np
import base64
import tensorflow as tf
import os
ポイントだけ説明すると、
Imageは画像データを読み込むために利用する。
numpyは画像データをベクトル化する際に利用する。
base64は画像データをテンプレート側のimgタグのsrcに直接読み込ませるために利用する。
続いて、前もって学習させておいた学習モデルをImportします。
#学習モデルのロード
from keras.models import load_model
model = load_model('C:\\django\\ML\\mnist.h5')
graph = tf.get_default_graph()
tf.get_default_graph()の部分で、ロードした学習モデルの計算グラフ情報を取得しています。
この辺はよくわかっていなかったのですが、計算グラフ情報を利用しないと以下のようなエラーが出るケースがありました。
画像ファイルUploadしてたら「Cannot interpret feed_dict key as Tensor」エラーが出るようになった。よくわからないけどググったら「load_modelを使って読み込んだモデルは、tf.get_default_graph()を使ってスレッド間で共有できるようにする必要がある。」らしい。ソースを真似して買えたら直った。
— Siny (@shinya_hd) December 16, 2018
続いて入力を受け取って結果を返す関数「mnist」の定義です。
def mnist(input):
global graph
with graph.as_default():
result = (model.predict(input, batch_size=None, verbose=0, steps=None)).argmax()
return result
次のコードでは、model.predict(入力データ).argmax()という形式で入力データに対して予測値(例えば数字の4だと[0,0,0,0,1,0,0,0,0,0])が返ってくるので、argmaxで最大値のIndex(4)を取得して、その値をreturnします。
続いて、ファイルをアップロードした際に呼ばれる関数を定義していきます。
以下、途中を省略してupload関数の全体を記載しています。
def upload(request):
#画像データの取得
files = request.FILES.getlist("files[]")
#簡易エラーチェック(jpg拡張子)
for memory_file in files:
root, ext = os.path.splitext(memory_file.name)
if ext != '.jpg':
message ="【ERROR】jpg以外の拡張子ファイルが指定されています。"
return render(request, 'mnist/index.html', {
"message": message,
})
if request.method =='POST' and files:
""学習結果を取得しテンプレートへ渡す"""
return render(request, 'mnist/result.html', context)
else:
return redirect('index')「判定」ボタンを押したときにupload関数が呼ばれるようにします。引数にリクエスト(request)を受け取ります。
files = request.FILES.getlist("files[]")
のように記載すると、複数ファイルのアップロードができるようになります。何かアップロードがあり、POSTメソッドならば学習モデルに画像データを渡して戻り値を取得してテンプレートへ渡す、そうでなければindexページへ単にリダイレクトするというフローにしています。
filesにはリスト型でファイル情報が入ってくるので、forループで1つずつ取り出し、拡張子が「.jpg」であるかどうかを判定して、jpgではない場合はエラーメッセージをテンプレートに返しています。
「root, ext = os.path.splitext(memory_file.name)」の部分でアップロードされたファイル名からファイル拡張子「.xxx」の部分をext変数に格納しています。
その後、extが「.jpg」と一致しない場合にエラーメッセージをテンプレートに渡しています。
#簡易エラーチェック(jpg拡張子)
for memory_file in files:
root, ext = os.path.splitext(memory_file.name)
if ext != '.jpg':
message ="【ERROR】jpg以外の拡張子ファイルが指定されています。"
return render(request, 'mnist/index.html', {
"message": message,
})
続いて以下の部分。
if request.method =='POST' and files:
result=[]
labels=[]
for file in files:
img = Image.open(file)
gray_img = img.convert('L')
img = gray_img.resize((28, 28))
img = np.array(img).reshape(1,28,28,1)
labels.append(mnist(img))
ファイルがアップロードされていた場合(POSTメソッド&filesが存在する)、filesから1つずつファイル情報を取り出し以下の処理を繰り返します。
・Image.open(ファイル名)でファイルをオープン
・img.convert('L')で画像をグレースケール化
・gray_img.resize((28, 28))で入力データを28x28ピクセルにリサイズ
・np.array(img).reshape(1,28,28,1)で学習モデルが受け付ける形状に変換
・最後にmnist(img)でminist関数にimgデータを渡して、判定結果を行け取り、labelsリストに
戻り値を追加
forループで全ファイル分処理が回ると、labels変数に画像の判定結果がリストとして格納されます。
※ labels=[0,1,4,9,5]のような感じです。
次に以下の部分。
for file, label in zip(files, labels):
file.seek(0)
file_name = file
src = base64.b64encode(file.read())
src = str(src)[2:-1]
result.append((src, label))
アップロードされた画像データ(src)と推論した結果(labels)をタプル形式でresult変数に追加していきます。
この辺のノウハウはnaritoさんのblog記事を参考にさせていただきました。
最後に以下の部分で画像データ(src)と推論結果(result)をテンプレートへ渡しています。
context = {
'result': result
}
return render(request, 'mnist/result.html', context)
views.pyの全体コードは以下の通りです。
from django.shortcuts import render, redirect
from PIL import Image
import numpy as np
import base64
import tensorflow as tf
import os
#学習モデルのロード
from keras.models import load_model
model = load_model('C:\\django\\ML\\mnist.h5')
graph = tf.get_default_graph()
def upload(request):
#画像データの取得
files = request.FILES.getlist("files[]")
#簡易エラーチェック(jpg拡張子)
for memory_file in files:
root, ext = os.path.splitext(memory_file.name)
if ext != '.jpg':
message ="【ERROR】jpg以外の拡張子ファイルが指定されています。"
return render(request, 'mnist/index.html', {
"message": message,
})
if request.method =='POST' and files:
result=[]
labels=[]
for file in files:
img = Image.open(file)
gray_img = img.convert('L')
img = gray_img.resize((28, 28))
img = np.array(img).reshape(1,28,28,1)
labels.append(mnist(img))
for file, label in zip(files, labels):
file.seek(0)
file_name = file
src = base64.b64encode(file.read())
src = str(src)[2:-1]
result.append((src, label))
context = {
'result': result
}
return render(request, 'mnist/result.html', context)
else:
return redirect('index')
def mnist(input):
global graph
with graph.as_default():
result = (model.predict(input, batch_size=None, verbose=0, steps=None)).argmax()
return result
続いてURLパターン(urls.py)の設定です。
from django.contrib import admin
from django.urls import path
from django.conf.urls import include
urlpatterns = [
path('admin/', admin.site.urls),
path('mnist/', include('mnist.urls')),
]ここは単純にmnistアプリケーションのurls.pyをインクルードしているだけです。
続いてアプリケーション(mnist)直下のurls.pyの設定です。
from django.contrib import admin
from django.urls import path
from django.views.generic import TemplateView
from . import views
urlpatterns = [
path('', TemplateView.as_view(template_name='mnist/index.html'), name='index'),
path('upload/', views.upload, name='upload'),
]TemplateViewを使ってTOPページ(index.html)を定義しています。
もう1つは「判定」ボタンが押されたときに呼ばれるuploadのURLパターンを定義しています。
URLパターンの設定は以上です。
URLの設定については特段難しい点はないと思います。
最後にテンプレートの設定です。
②index.html(TOP画面)
③result.html(判定結果画面)
まずは共通テンプレートです。
全体コードは以下の通りです。
{% load static %}
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
{# Bootstrap4を使う #}
<!-- linkタグでbootstrapのcssファイルを読み込む -->
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css">
<!-- linkタグでcommon.cssファイルを読み込む -->
<link rel="stylesheet" href="{% static 'css/common.css' %}">
<!-- タイトルの設定-->
<title>Tutorial</title>
<body>
{% block content %}
<!-- 子テンプレートの内容がIncludeされる -->
{% endblock %}
<!-- bootstrapのjavascrit読み込み-->
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/js/bootstrap.min.js"></script>
</body>
</html>特段難しい部分はないです。
以下の部分でbootstrapのcssとjsファイルを読み込んでいるくらいですね。
<linkrel="stylesheet"href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css">
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/js/bootstrap.min.js"></script>
②index.html(TOP画面)
続いてindex.html(TOP画面)です。
<!-- 親テンプレートを読み込む-->
{% extends './base.html' %}
{% load static %}
{% block content %}
<div class="content-wrapper">
<div class="container-fluid">
<div class="mt-5 text-center">
<div class="alert alert-primary alert-dismissible" role="alert">
<p style="margin-bottom:1em;"><h3><b>手書き文字判定AIアプリの説明</b></h3></p>
<hr>
<h4>
<ol>
<li style="margin-bottom:1em;" align="left">数字(0~9)を手書きしたjpgファイル画像をアップロード後に「判定」
ボタンを押してください。</li>
<li style="margin-bottom:1em;" align="left">ファイル画像の形式は<font color=red>「JPG」</font>、背景色は
<font color=red>「黒」</font>、文字は<font color=red>「白」</font>で作成してください。</li>
<li style="margin-bottom:1em;" align="left">アップロードされた画像の特徴を解析してAIが数字の0~9いづれかを
自動判定します。</li>
<li style="margin-bottom:1em;" align="left">チュートリアル簡易用の学習モデルのため、上記以外のルールで作成
した画像は正しく判定されません。</li>
<li style="margin-bottom:1em;" align="left">画像サイズは28*28ピクセルにすると判定確率が高くなります。</li>
<li style="margin-bottom:1em;" align="left">画像ファイルは複数同時に選択してアップロードすることができます。</li>
</ol>
</h4>
</div>
</div>
<hr>
<form action="{% url 'upload' %}" method="POST" enctype="multipart/form-data">
<div style="display:inline-flex">
<input type="file" name="files[]" multiple>
</div>
<input type="submit" class="btn btn-lg btn-danger" value="判定">
{% csrf_token %}
</form>
{% if message %}
<div class="alert alert-danger" role="alert">
<h4><font color="red">{{message}}<br></font> </h4>
</div>
{% endif %}
<hr>
<h4><p style="margin-bottom:1em;">入力数字画像データ例</p></h4>
<!-- 画像表示 -->
<div class="container">
<div class="row">
<div class="col-xs-3">
<div class="thumbnail">
<img src="{% static 'img/sample1.jpg' %}" width="45px" height="45px">
<div class="caption">数字(8)</div>
</div>
</div>
<div class="col-xs-3">
<div class="thumbnail">
<img src="{% static 'img/sample2.jpg' %}" width="45px" height="45px">
<div class="caption">数字(6)</div>
</div>
</div>
<div class="col-xs-3">
<div class="thumbnail">
<img src="{% static 'img/sample3.jpg' %}" width="45px" height="45px">
<div class="caption">数字(3)</div>
</div>
</div>
</div>
</div>
<!-- 画像表示 -->
</div>
</div>
{% endblock content %}
デザイン部分の詳細説明は割愛して、ポイントだけ説明します。
以下の部分で、POSTメソッドでupload関数を呼び出すように逆引き設定しています。
<form action="{% url 'upload' %}" method="POST" enctype="multipart/form-data">次に以下のコード。
<div style="display:inline-flex">
<input type="file" name="files[]" multiple>
</div>
<input type="submit" class="btn btn-lg btn-danger" value="判定">input typeをfile、nameをfiles[]に設定しています。
views.pyの以下のコードでこのnameに指定したfiles[]を使用しています。
以下の部分で、jpgファイル以外をアップロードした場合にエラーメッセージを表示させています。
{% if message %}
<div class="alert alert-danger" role="alert">
<h4><font color="red">{{message}}<br></font> </h4>
</div>
{% endif %}
以下は、サンプルの手書き数字画像をWEZ上に表示しているだけです。
<!-- 画像表示 -->
<div class="container">
<div class="row">
<div class="col-xs-3">
<div class="thumbnail">
<img src="{% static 'img/sample1.jpg' %}" width="45px" height="45px">
<div class="caption">数字(8)</div>
</div>
</div>
<div class="col-xs-3">
<div class="thumbnail">
<img src="{% static 'img/sample2.jpg' %}" width="45px" height="45px">
<div class="caption">数字(6)</div>
</div>
</div>
<div class="col-xs-3">
<div class="thumbnail">
<img src="{% static 'img/sample3.jpg' %}" width="45px" height="45px">
<div class="caption">数字(3)</div>
</div>
</div>
</div>
</div>
<!-- 画像表示 -->
以上でindex.htmlは完了です。
③result.html(判定結果画面)
最後にresult.htmlです。
<!-- 親テンプレートを読み込む-->
{% extends './base.html' %}
{% load static %}
{% block content %}
<div class="content-wrapper">
<div class="container-fluid">
<div class="card mb-3">
<div class="card-header">
<h2><b>手書き文字判定AIアプリ</b></h2></div>
<div class="card-body">
<div class="mt-5 text-center">
<div class="alert alert-primary alert-dismissible" role="alert">
<h3 class=""><b>判定結果</b></h3>
<hr>
<div class="mt-5 text-center">
{% for data in result %}
<div class="alert alert-warning">
<img src="data:image/jpg;base64,{{data.0}}" width="72" height="72" />
<p class="lead">【AIの判定結果】<br>画像は<font color=red><b>{{ data.1 }}</font></b>です。</p>
</div>
{% endfor %}
<a class="btn btn-lg btn-secondary" href="{% url 'index' %}">戻る</a>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
{% endblock content %}
まずは最初の3行。
extendsで共通テンプレートを拡張します。
load staticはサンプル例の画像ファイルを表示させるのに利用します。
block content以下に結果を表示するコードを書いていきます。
<!-- 親テンプレートを読み込む-->
{% extends './base.html' %}
{% load static %}
{% block content %}続いて以下の部分。
{% for data in result %}
<div class="alert alert-dark alert-dismissible" role="alert">
<img src="data:image/jpg;base64,{{data.0}}" width="72" height="72" />
<p class="lead">【AIの判定結果】<br>画像は<font color=red><b>{{ data.1 }}</font></b>です。</p>
</div>
{% endfor %}{% for data in result %}
~~結果表示~~
{% endfor %}
という感じで、views.pyから受け取った画像データと推論結果が格納されているresultオブジェクトを受け取り、結果を表示していきます。
画像データの表示部分は、以下の通りimgタグに「data:image/jpg;base64,」をつけます。
<img src="data:image/jpg;base64,{{data.0}}">
以上で完了です。
これで、「http://127.0.0.1:8000/mnist/」にアクセスして以下のような画面が表示されればOKです。
user@sinyblog:~/article ❯ 07_section_7.md参考にした書籍
今回のWEBアプリを作成する際に参考にした書籍を紹介しておきます。

この書籍は、DeapLearningの基礎的な説明から始まり、実際のコードを理解する上で必須となるベクトル等の数学的概念、この記事でもでてくるkerasのImageDataGeneratorの扱い方も説明されていて、これまで購入した書籍のなかで一番のお勧めで、現在も学習に使っています。
Djangoの書籍は、やっぱりakiyokoさんの以下の書籍がお勧めで、私も2冊とも所有しています。
あとは、naritoさんのblogもよく利用させて頂いております。
(質問にも丁寧に回答していただけます!)
user@sinyblog:~/article ❯ 08_section_8.mdまとめ
後半はちょっと駆け足になってしまいましたが、MNISTデータを使った前処理~学習~ウェブアプリ化まで一通り説明しました。
今回は簡易的な学習モデルなので、28x28以外の画像サイズを与えた場合はちょくちょく判定を誤りますが、通常のMNISTチュートリアル通りにやるよりは多少汎用性があると思います。
あとは、これをベースとして以下のようなアプローチも試していきたいな~と思っています。
・データ拡張で精度をアップさせる。
・背景が黒だけでなく、白の場合等でも正確に判定できるモデルを作る。
・ネットワークのモデルをいろいろチューニングしてみる。(活性化関数、学習率、Dropout等)
・手書き数字画像ではなく他の事例への応用を試してみる。
たとえば・・
例1)手書きの記号画像「★、□、■、▲、△」等を与えた際に、回答として
「これは星です。」
「これは白い四角です。」
といった回答をするアプリを作ってみる。
例2)違反品と正常品の画像を入力データに与えて学習させておき、新規のデータが
来た場合にその画像が違反品かどうかを自動判定させる。
これはメルカリなんかで実装されている違反品の出品を投稿された画像から自動検知させるような例ですね。
こんな感じで、今回のMNISTデモアプリをベースにいろいろと発展させていけるのではないかなと思っています。
※この記事が良かったと思う方はTwitterフォロー(shiny)とリツイート頂けると嬉しいです!