こんにちは。sinyです。
この記事ではディープラーニングの画像生成手法の1つであるGANについて初学者向けに要点をまとめました。
※基本的には専門書をベースに情報整理していますが、記載誤りなどありましたらご指摘いただけますと幸いです。
GANとは?
GANとはGenerative Adversarial Networkの略で、ニューラルネットワークを使うことでリアルな画像データを生成することが可能な機械学習(ディープラーニング)のことです。
通常のニューラルネットワークとの大きな違いは、生成器と識別機という2つのニューラルネットワークを使う点です。
生成器は、何もないランダムなベクトルから訓練データとそっくりな画像を作り出すことを目標に学習します。
一方、識別機は生成器が作り出した偽物の情報と本物の情報(訓練データ)を正確に見分けることを目標に学習していきます。
生成器と識別機
生成器と識別機についてもう少し詳細に見ていきます。
まず、生成器と識別機の入力、出力、目的をまとめると以下の通りです。
| 生成器(Generator) | 識別機(Discriminator) | |
| 入力 | 乱数ベクトル | ・本物のデータ ・生成器が作った偽データ |
| 出力 | 本物そっくりなデータ | ・本物のデータが本物である推定確率 ・生成器が作った偽データの推定確率 |
| 目的 | 本物と見分けのつかない偽のデータを生成すること | 本物のデータと生成器が作った偽データを見分けること |
識別機(Discriminator)
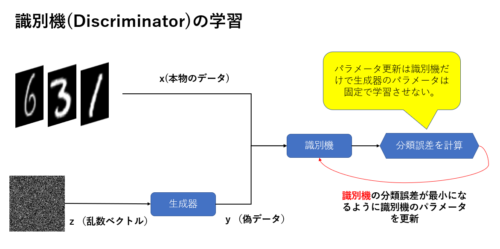
識別器の学習は以下の流れで行います。
- 訓練データ(本物のデータ)からランダムにデータxを取り出す。
- 新しい乱数ベクトルzを生成し、生成器を使って偽のデータyを生成する。
- 識別機ネットワークを使って本物のデータと偽物データの分類誤差を計算し、逆誤差伝搬でパラメータを更新して誤差が最小になるように学習する。
ポイントは、「識別機の分類誤差が最小になるように識別機のパラメータを更新」する点です。
また、識別機の学習時に生成器のパラメータは更新しません。
生成器(Generator)
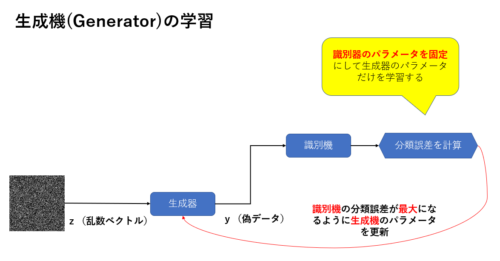
続いて、生成器の学習は以下の流れで行います。
- 乱数ベクトルを生成して生成器で偽データyを生成する
- 識別ネットワークで偽データyが本物かどうかを分類する
- 分類誤差を計算して生成器のパラメータを更新(識別機の誤差が最大になるように学習する)
→偽のデータyが正解であるように学習させる。
ポイントは、「識別機の分類誤差が最大になるように生成機のパラメータを更新」する点です。
また、生成器の学習時は識別機のパラメータを固定にして更新されないようにします。
GANの学習はいつまで行うのか?
通常のディープラーニングの学習では正解率等の明確な目標値があり、過学習し始めたところで学習を止めたりしますが、GANでは生成器と識別器は相対する存在なので一方の精度が上がれば他方の精度は低下し、片方が何かを得ると他方がその分を失います。
そのうち自分の行動を変えても他方の状況を改善できなくなるという「ナッシュ均衡」状態に陥ります。
GANではこのナッシュ均衡状態になったときに学習が収束したということができます。
GANでは以下の条件を満たした場合にナッシュ均衡状態になったといえます。
- 生成器が本物のデータを見分けのつかない偽データを生成する。
- 識別機は入力されたデータが本物か偽物かを50%の確率でしか推定できなくなる。
お勧めの書籍
ディープラーニングに関する技術書は多数リリースされていますが、2020年に入って初めてGANを専門に取り扱った技術書が発売されました。
それが以下の書籍「実践GAN(敵対的生成ネットワークによる深層学習)」です。
リリース直後に即購入しましたが、これまでGANだけを取り扱った技術書はありませんでしたのでGANを深く学びたい方にはお勧めです。
なお、この書籍はKerasをベースとしていて、単純な全結合層からなるGANから始まり、DCGAN、半教師ありGAN、条件付きGAN、CycleGANと順を追って応用を学べる内容になっています。
特にGANの仕組みについては初学者向けにわかりやすく丁寧に説明されているので、これからGANを学びたいという方にはお勧めです。
以上、ディープラーニングGANの基礎まとめ【初心者向け】でした。