こんにちは。sinyです。
この記事は条件付きGAN(CGAN: Conditional GAN)の仕組みについて学習した際の情報のまとめ記事です。
数式は一切用いず、全体の仕組みを理解しやすいように図解でまとめましたので、初学者の方のお役に立てれば幸いです。
※記載誤りなどあればご指摘いただけますと助かります。
条件付きGANとは?
条件付きGAN(以降CGANと記載)とは、生成器と識別機に画像データに加えて追加の条件情報を与えることで条件付けができるように訓練を行うGANです。
ここで追加する条件情報は何でもよいようですが、ここではラベル情報を使う前提で説明します。
もっとわかりやすく簡潔に言うと、指定した条件にマッチするような画像を生成することができるのがSGANです。
例えば、0~9の数字を生成するように学習すると、「数字の3を生成」といったように生成させたい画像を指定できるわけです。
この点がDCGANなどと大きく違う点です。
CGANは本物のデータかつラベルが正しくマッチングしている組み合わせのみ受け入れて、それ以外のパターンはすべて拒否する形で学習します。
具体例を以下に示します。
パターン1:生成器が作り出した偽のデータ(3, 3) → 拒否する
パターン2:生成器が作り出した偽のデータ(3, 4) → 拒否する
パターン3:本物のデータ(3, 3) → 受け入れる
パターン4:本物のデータ(5, 3) → 拒否する
また、CGANはDCGANと違い入力がどのクラスに属するかは学習しません。

CGANの生成器の概要
生成器の目的は本物そっくりなデータであり、且つラベル(y)とマッチしている偽のサンプルを生成することです。
CGANの生成器の詳細については下図の通りです。
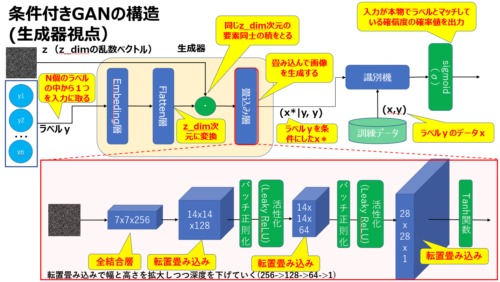
生成器は乱数ベクトルzとラベルy(N子のラベルの中の1つ)を入力として受け取り、偽のサンプル(x*|y)を生成します。
※(x*|y)というのはyというラベルが与えられた時に生成される偽のデータ(x*)という意味
- 入力は2つ:乱数ベクトルzとラベルy
- 出力は1つ:偽のサンプルデータ
入力~出力までのロジックをもう少し詳細に見ていきます。
上図にも記載してありますが、以下のような流れで偽のデータを生成します。
- ラベルyをEmbedding層に入力して蜜ベクトルに変換する(z_dim:例えば100次元)
- ラベルyをベクトルに変換したもの(100次元)と乱数ベクトルz(100次元)同士の要素の積を計算し復合表現を生成する
※注意:内積ではなく各要素毎の積 - 生成した複合表現ベクトルを畳み込み層に入力して画像を生成する。
※図で説明している畳み込み層ネットワークはDCGAN等で用いるものと基本的に同じと考えてよい。
CGANの識別器の概要
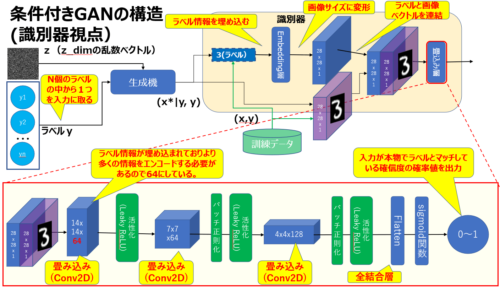
識別器の目的は、偽物のデータ+ラベルの組と、本物のデータ+ラベルの組合わせを見分けることです。
- 入力1:乱数ベクトルzとラベルyの組み合わせ(x*|y, y)
- 入力2:本物のデータとラベルyの組み合わせ(x, y)
- 出力:入力が本物でラベルとマッチしている確信度を表す確率値
CGANの識別器では、生成器からのサンプルと本物のサンプルを受け取ります。
また、どちらのサンプルに対しても同じラベル(y)を利用します。
- ラベルyをEmbedding層に入力して1画像と同じサイズのベクトルを作る(例えばmnistの画像データなら28 x 28 x 1)
- 1で生成したラベル情報を埋め込んだ画像と入力画像を重ねて複合表現を生成する。
※形状としては(28 x 28 x 2)のようになる
※ここで記載している入力画像は生成器が作り出した画像 or 本物の画像データを指します。 - 複合表現をCGANの識別器ネットワークに入力し、出力を得る。
なお、CGANの識別器ネットワークはDCGANなどで使われるものと基本的に同じですが、入力にラベル情報と画像情報を含んでいるので、下図の通り入力の次元が少し異なります。
最初の畳み込み層では、ラベル情報を含んでいる分より多くの情報をエンコードする必要があるという理由で層の深さを64に増やしています。
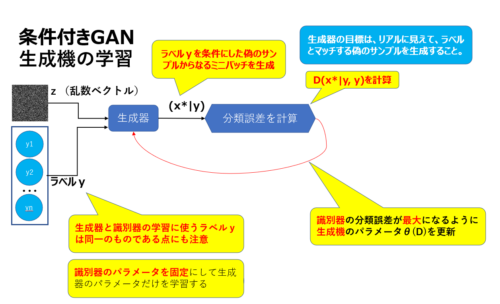
CGANの生成器の学習
CGAN生成器の学習については基本的に特殊な点はなく、下図の通り乱数ベクトルzとラベルの組み合わせ(z,y)を生成器ネットワークに入力し、生成された偽のサンプル(x*)とラベルyの誤差を計算し、逆誤差伝搬で識別器の分類誤差が最大になるように生成器のパラメータθ(G)を更新します。
「識別器の分類誤差が最大になるように」という部分は、具体的には生成されたサンプルが本物のラベル(ラベル=1)になるように学習させます。
また、生成器の学習時は、識別器のパラメータが更新されないように識別器ネットワークのパラメータを固定にします。
CGANの識別器の学習
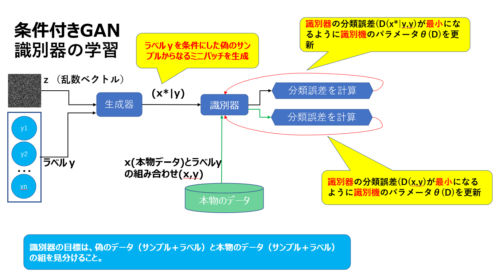
最後にCGANの識別器の学習ですが、2つの学習があります。
1つ目が、本物のサンプルとラベルを入力に受け取り、分類誤差D(x, y)を計算してその誤差が最小(本物のラベル1に近づくように)になるように識別器のパラメータθ(D)を更新していきます。
2つ目が、乱数ベクトルから生成した偽のデータx*とラベルyを受け取り、分類誤差D(x*|y, y)を計算してその誤差が最小(偽物のラベル0に近づくように)になるように識別器のパラメータθ(D)を更新していきます。
参考にした情報
本記事は以下の情報を参考に情報をまとめました。
以上、「条件付きGAN(CGAN)の仕組みを数式なしで図解【初心者向け】」でした。