目次
こんにちは。sinyです。
昨年G検定に合格してからも、少しずつですがディープラーニングの勉強も継続しています。
業務経験ゼロなので偉そうなことは全く言えないのですが、最近受講したディープラーニングを用いた異常検知セミナーの知識を使って、実際に業務に生かせる領域がないかちょっとだけ探ってみましたので、考察をまとめました。
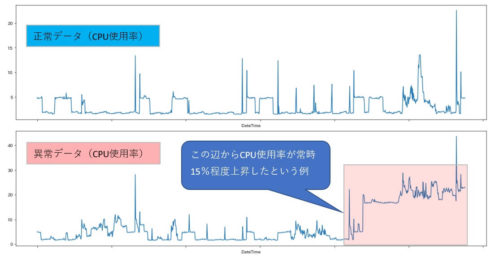
事例としては、「あるサーバのリソース使用率がある時間を境に15%ほど常時上昇し始めた(何かの障害予兆)というケースをディープラーニングで検知できないか?」というものです。
統計的手法を用いればこのようなケースも検知できる手段はあると思いますが、今回はディープラーニングでなんとかできるものなのか?という観点で試行してみました。
ディープラーニングにおける時系列データの異常検知方法
ディープラーニングにおける異常検知にはいろんな方法があると思いますが、今回は簡単な時系列データに対してディープラーニングのオートエンコーダを使った異常検知の手法について触れてみます。
オートエンコーダとは?
よくあるディープラーニングの画像認識では、正解データがあって、入力データを与えた場合に正解を答えるように学習させていきます(いわゆる教師あり学習)が、異常検知の世界では、そもそも異常データ自体が極めて少ないためラベルとなる正解データがありません。
そこで、逆の発想で正解データだけを使って正解データを出力するような学習モデルを作ることで、正常とは違うパターンのデータがやってきたときに「上手く情報を復元できない」という特性を生かしたものが、このオートエンコーダという手法なんですね。
オートエンコーダ(AutoEncoder)とは、入力と出力が同じになるようにニューラルネットワークを学習させるような手法で、以下のような構成をしています。
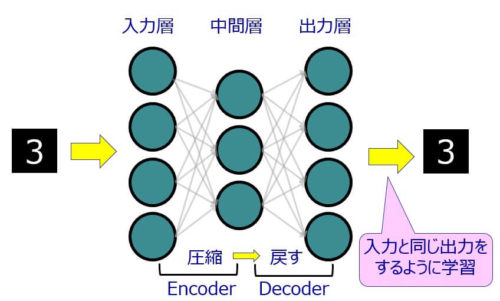
入力データをエンコーダ(Encoder)で圧縮して、圧縮したデータをデコーダ(Decoder)で元に戻すようなネットワーク構成で、入力と出力に同じデータを与えて学習させることで、入力と同じ出力を出すようなネットワークの重みを学習させるニューラルネットワークになっています。
また、基本的には以下のような特徴があります。
- 入力層と出力層のユニット数は同じ
- 入力層~中間層までをエンコーダ(Encoder)と言います。
- 中間層~出力層までをデコーダ(Decoder)と言います。
- 基本的には中間層のユニット数は入力層より少ない。
→この場合、入力データを圧縮していることになる。(より特徴的なデータだけを保持)
ただし、中間層のユニット数が入力層より多いオートエンコーダというものも存在していて、このような構成のオートエンコーダのことを「スパースオートエンコーダ」と言うそうです。
スパースオートエンコーダのメリットは、ユニット数を多くした中間層に対して、「スパース正則化項」と呼ばれるペナルティ関数を与えることで大部分の中間層のユニットの値を0(情報を伝えない)にしてしまうことでシンプルな構造にしようという考え方で、このようにすることで過学習を抑える効果があるようです。
今回は、このスパースオートエンコーダというものも使ってみます。
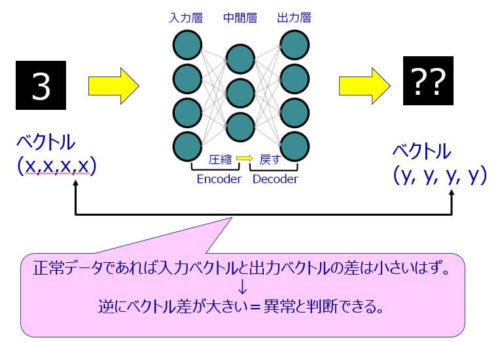
異常はどうやって判定するの?
オートエンコーダで学習したモデルは、正常なデータしか復元できないモデルになっているので、異常データが入ってきた場合に復元したデータは、正常データと大きく異なっているはずなので、入力データと出力データの差を見ることで異常度を判定することができます。
実際には、入力データと出力データはベクトル値なので、このベクトルの差を計算することで異常度を判定するわけです。
オートエンコーダの実装
今回は、kerasを使って時系列データの異常検知サンプルプログラムを作ってみました。
冒頭でも説明しましたが、あるサーバのCPU使用率がある時間を境に15%程度使用率が常時上昇し始めたという異常性をオートエンコーダで検知してみたいと思います。
学習データとテストデータとしては、以下のようなCPU使用率のデータを使いました。
(CPU使用率自体はどちらのデータも0~40%程度の低使用率のデータになっています)
以下、実装したプログラムについて簡単に説明します。
CSVファイルの読み込み
まずは、学習データとテストデータ(CSVファイル)を読み込みます。
test_df = pd.read_csv('cpu_data_test.csv', usecols=[1])
train_df = pd.read_csv('cpu_data_train.csv',usecols=[1])データは以下のような形式です。

Windowサイズ100の入力用時系列データセットを生成
# (279, 10)の入れ物 seqを用意して0行目から10時点のデータをセット。
# 次の列には古いデータを1つだけ捨て、新しいデータを1つ加えた10個のデータをセット、これを最後まで繰り返す。
# [ 古いデータ → 新しいデータ] 10セット分
def subseq(x, w):
seq = np.zeros((len(x) - w + 1, w))
x_np = x.iloc[:, 0]
for i in range(len(x) - w + 1):
seq[i, :] = x_np[i:w+i]
return pd.DataFrame(seq)
w_size = 100 # ウィンドウサイズ
X_train = subseq(train_df, w_size)
X_test = subseq(test_df, w_size)上記プログラムを実行すると以下のような10時点毎にずらしたデータセットが出来上がります。
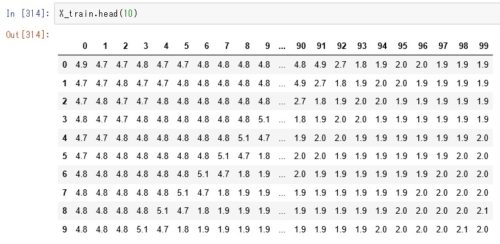
この時点で、X_train(学習用)とX_test(テスト用)データには(1053,100)次元のデータセットができあがります。
データが0~1に収まるように正規化する。
続いて、データは0~100の任意の数値なので、0~1に収まるように正規化しておきます。
今回は、ScikitLearnのMinMaxScalerを使って、データを0から1の範囲に正規化しました。
sc = MinMaxScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.fit_transform(X_test
モデルの定義(KERAS)
モデルは複雑にしないほうがよさそうだったので、シンプルに3層構造にして、中間層にスパースオートエンコーダを設定しました。
「activity_regularizer=regularizers.l1(l1))」 という部分がスパースオートエンコーダの指定になっています。
l1=10e-7 # L1正則化のパラメータ
enc_dim = 160 # 隠れ層のユニット数
input_layer = Input(shape=(w_size,))
encoded = Dense(enc_dim, activation='relu',
activity_regularizer=regularizers.l1(l1))(input_layer)
decoded = Dense(w_size, activation='relu')(encoded)
autoencoder = Model(inputs=input_layer,
outputs=decoded)
モデルの形状は以下の通りです。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 100) 0
_________________________________________________________________
dense_5 (Dense) (None, 160) 16160
_________________________________________________________________
dense_6 (Dense) (None, 100) 16100
=================================================================
Total params: 32,260
Trainable params: 32,260
Non-trainable params: 0
_________________________________________________________________
パラメータの指定
オプティマイザに「adadelta」、損失関数に「crossentropy」を指定しています。
autoencoder.compile(optimizer='adadelta',
loss='binary_crossentropy')学習の実行
エポック数は1000回にしてみました(あまり深い理由はないです)
ここで、オートエンコーダのポイントですが、入力とラベルデータに同じ
「X_train」を指定しています。
こうすることで、入力データを正解データとして学習させることができます。
epochs = 1000
history = autoencoder.fit(X_train,
X_train,
epochs=epochs,
batch_size=None,
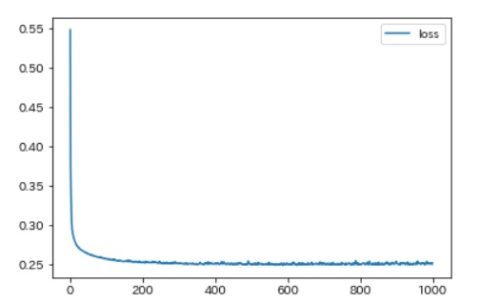
verbose=1)損失値のチェック
pd.DataFrame(history.history['loss'], columns=['loss']).plot()LOSSは以下のような感じになりました。
200回くらいで収束してそうなので1000エポックも実行する必要はなかったかもしれませんね・・
考察
まずは、predictメソッドを使ってテストデータ(X_test)を与えて予測結果をdecoded変数に格納します。
decoded = pd.DataFrame(autoencoder.predict(X_test))
異常度としては、予測結果(decoded)と入力データ(X_test)の平均二乗誤差を求めて確認してみます。
ちなみに、decodeもX_testも(1053, 100)次元のデータになっています。
dist = np.sqrt( np.sum( (decoded - X_test)**2, axis=1))上記(平均二乗誤差)をプロットすると、以下のような感じになりました。
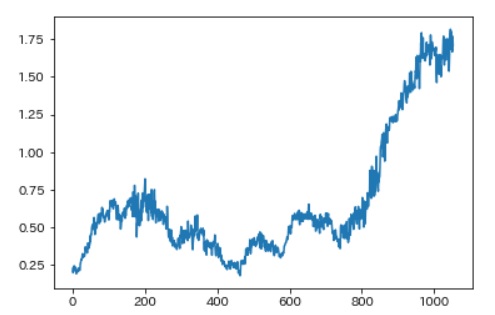
これだけ見ててもよくわからないので、テストデータに重ねてみます。
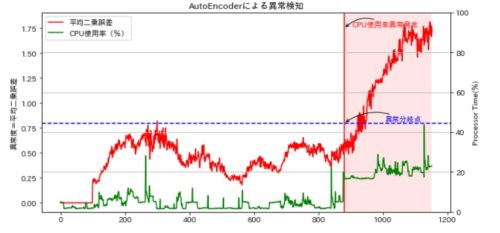
赤線が異常度、緑線がCPU使用率を示しています。
X軸が880あたりからCPUの使用率が15%ほど常時上がり始めている(異常発生ポイント)のですが、このタイミングから異常曲線も上昇に転じているのがわかるかと思います。
全体としてCPU使用率のMAXは35~40%に収まっていて、前半(X軸が280あたり)のCPU上昇ではさほど異常値はあがらず、X軸の880あたりを境にCPU上昇の特徴を捉えて異常値がいい感じで上昇してくれています。
何となくですが、このケースのデータではいい感じの結果になりました。
ただ、実際にはどの時点のデータを正常とみなして学習させるかによって、異常度の判定がぶれていくと思うので、実運用に適用するにはもっといろんなケースで検証が必要そうです。
素人意見ではありますが、何となくディープラーニングを使うとシステムの特性を把握したうえで適切な学習モデルを作ってあげれば、サーバ監視の領域では効果的に異常を検知できる可能性があるのではないかなと思いました。
もう少しいろんなケースで検証を続けていきたいと思います。
本記事の続編の記事がありますので、こちらも参考にどうぞ。