目次
こんにちは。sinyです。
2019年はAI分野において自然言語処理(NLP)が飛躍的に発展していく年になると思っているのですが、これからNLPにチャレンジしたいという入門者向けに自然言語処理でできること、その概要についてまとめてみました。
すこしでも参考になれば幸いです!
自然言語処理とは?
機械学習やディープラーニングの勉強を進めていくと、「自然言語処理」という言葉がよく出てきます。
自然言語処理(NLP)は「Natural Language Processing」の略で、いわゆる人間が用いる言葉のことを言います。

PythonやJavaといった言語は「プログラム言語」といい、同じ「言語」とつくけどNLPとは全く違う意味で用いられます。
そもそも言語(言葉)ってなんぞや?
最近、AIの領域でも流行りつつある自然言語処理ですが、簡単に言うと人が扱う言葉をコンピュータに理解させようという学問領域のことだといってよいと思います。
で、「そもそも言語ってなんぞや?」というところから話したいと思います。
まず、大前提として「言語」自体に意味はなく、単なる記号に過ぎないということです。
例えば以下のような例を考えてみましょう。
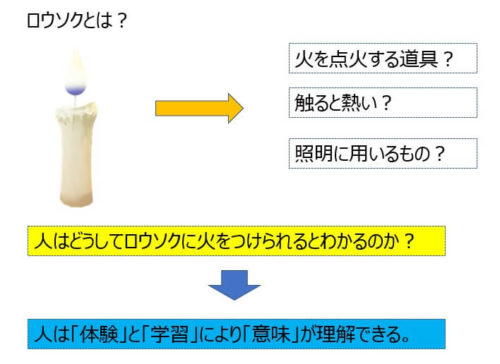
人が、「言語」の意味を理解できるのは、体験によってその言語(ロウソク)の意味(ロウソクは火をつけるもの/照明に使える・・・など)を理解できるようになるからであって、言語自体(ロウソク)はただの記号に過ぎないわけです。
そして、
「言語をコンピューターに理解させるにはどうしたらよいか?」
というのが、自然言語処理の難しいところです。
シンボル・グラウンディング問題とは?
ここで、押さえておきたい言語として「シンボル・グラウンディング問題」という言葉があります。
これは、「言語という意味のないものに対して、どうやって意味、概念を結びつけるか?」という問題で、この問題が解決できないと自然言語処理を実現することができないわけです。
自然言語処理でできることは?
自然言語処理を利用するといろいろなことができるようになります。
既に世の中で利用されているサービスとしては、以下のようなものがあります。
- Google翻訳(英語⇒日本語へ自動翻訳など)
- スマートスピーカー(アレクサなど)
- チャットボット(ユーザからの質問に自動応答してくれる)
- 文章の自動要約
他にも様々な領域で活用できる可能性があります。
自然言語処理で押さえておきたいポイント
自然言語処理で押さえておきたいポイントを2つ挙げておきます。
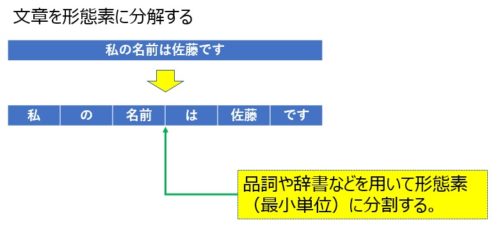
①形態素解析
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。
形態素解析エンジンとしてMeCabが有名ですが、基本的にはLinux,Ubuntu環境向けでWindowsでは環境構築がちょっとややこしいみたいです。
Windows環境でも簡単に利用できる形態素解析エンジンとしてJanomeというものがあります。
Janomeはpythonのpipコマンドでインポートするだけなので非常に簡単に利用できるのでお勧めです。
②係り受け構造解析
もう1つは「係り受け構造解析」です。
係り受け構造解析とは簡単に言うと、「ある単語がどこに係っているのか?」という関係性を解析するものです。

係り受け構造解析ができると、言葉の意味をよりコンピュータへ理解させることができるようになるわけです。
言語をコンピュータに理解させる方法は?
コンピュータに言語を理解させる方法としては、大きく以下の3つの方法があります。
ルールベース
まず1つ目は、ルールベースによる手法です。
これは至ってシンプルで、辞書や文法といったルールベースで言葉をコンピュータに理解させるという手法です。
人が1つ1つある単語について意味を割り当てていくので、非常に作業コストがかかりますし、時代が進むにつれてどんどん新しい言葉が生まれていくので、時代変化への対応が非常に困難という問題があり、あまり現実的な手法ではないです。
確率的言語モデル
自然言語処理を確率として扱うという考え方のモデルです。
モデルとしては、「単語ユニグラム」、「品詞N-gram」、「単語N-gram」といったモデルがあります。
詳細の説明は割愛しますが、ざっくりと文章を確率的に解析してその意味を捉えようとする考え方だと思ってもらえればよいかと思います。
ニューラル言語モデル
最後にニューラル言語モデルですが、これはニューラルネットワークを用いた言語モデルの総称のことで、今のところ自然言語処理では最先端のモデルになっています。
このモデルは一言で言うと「単語の意味は、その単語の周辺の単語によって決まる」という考え方に基づいた言語モデルです。
たとえば、「あつい」という言葉は様々な場面でつかわれますが、
「あつい紅茶」、「あつい板」
というように、「あつい」という言葉の周辺にくる言葉によって「あつい」の意味が決まるという考え方に基づいています。
現在、世の中に出回っている最先端の自然言語処理のサービスの多くは、この概念に基づいているようです。
自然言語処理関連の書籍
自然言語処理系の書籍はまだあまり多くないのですが、個人的に気になっている書籍を2つ挙げておきます。

こちらは最近発売された入門者向けの自然言語処理の書籍です。
以下のような目次になっていて、WEBアプリケーションを作りながら自然言語処理に関連するテーマを学べる内容になっています。
第1部:データの準備
●テキストデータの収集
●データベースへの格納
●検索エンジンへの登録
第2部:データの解析
●文法構造を調べる
●意味づけ
●知識データとの連係

もう一冊は、オライリー・ジャパンから出ている本です。
このシリーズはディープラーニング系もかなり好評な書籍なので、ぜひ手に取ってみたい1冊です。
まだ購入していませんが購入予定です。
以上、自然言語処理に関する簡単なまとめ記事でした。