目次
こんにちは。sinyです。
本記事では、前回の下記で収集した中古不動産情報に対してデータ分析をするために各種前処理を行っていきます。

前提
本記事では、不動産データ分析事例【pythonスクレイピング編】で中古不動産情報をcsvファイル(suumo_bukken.csv)として吐き出している前提で話を進めていきますので、まだ不動産情報をスクレイピングできていない方は記事を参考にしてcsvファイルを準備してください。
まず最初に収集したデータファイルの内容を簡単に確認します。
import requests
import pandas as pd
import re
df = pd.read_csv('data/suumo_bukken.csv', index_col=0)
df.head()
上記コードを実行すると以下のようなデータ(物件名、住所、最寄り駅、築年数、価格、間取り、面積、バルコニーの広さ)が表示されます。

続いて、df.info()でデータの情報を確認してみます。
以下の通りobjectタイプのカラムであることがわかります。
df.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 6311 entries, 0 to 6310 Data columns (total 8 columns): 物件名 6311 non-null object 住所 6311 non-null object 最寄り駅 6311 non-null object 築年数 6311 non-null object 価格 6311 non-null object 間取り 6311 non-null object 面積 6311 non-null object バルコニーの広さ 6311 non-null object dtypes: object(8) memory usage: 443.7+ KB
念のため欠損値がないかどうかも確認しておきます。
物件名 0 住所 0 最寄り駅 0 築年数 0 価格 0 間取り 0 面積 0 バルコニーの広さ 0 dtype: int64
今回はすべてのカラムで欠損値が0であることが確認できました。
※もし、欠損値があった場合は欠損値を削除するか、補完する必要があります。
データ前処理の方針
データ分析をするためには基本的に数値にできるものは数値化し、分析に必要な特徴量が不足している場合で、既存のデータから生成できるものがある場合は、それらのデータを加工してほしい情報を作っていきます。
今回は以下のようなデータ加工(前処理)を行っていきます。
- 住所から県名と市区町村名を生成する。
-
築年数が「1973年3月」のようになっているので、現在日時を基準に月数に変換する。
-
価格が「**万円、**億円」と文字列を含んでいるので「文字」から「数値」(万単位)に変換する。
-
面積、バルコニーの広さがobject型になっているので数値型(float)に変換する。
-
「不動産単価(1平米あたり何万円か?)」欄を新設する。
-
間取りから「部屋数」欄を作成する。
-
最寄り駅から「路線」、「駅名」、「手段」、「時間」に分ける。
それでは1つ1つ前処理を行っていきましょう。
データの前処理
住所から県と市区町村情報を生成する
「住所」の値を見ると「埼玉県狭山市大字青柳」といったように「県名」と「**市」といった情報が混ざっているため2つのデータに分割し、新たな項目「都県」と「市区」を作ります。
分割するには住所の情報を「都、県」で分割した左側の値を取得すればいいのでre.splitメソッドを使って分割後の1番目の要素(県名)を取得します。
同様に市区町村の部分は「都 or 県 or 市 or 区」で区切った時の2番目の要素を取得すればいいので同様にre.splitメソッドを使い2番目の要素を取得します。
コードにすると以下のようになります。
# 文字列を複数文字で split
df['都県'] = df['住所'].apply(lambda x: re.split('[都県]', x)[0])
df['市区'] = df['住所'].apply(lambda x: re.split('[都県市区]', x)[1])
df.head()
df.head()で確認すると、以下のように新しく「都県」と「市区」という列が追加され、それぞれ県名と市区町村名が格納されていることが確認できるかと思います。

築年数を現在日時を基準に月数に変換する
まず、「築年数」のデータを見ると値として「月」が入っていないデータがいくつかあるので、「月」情報がないデータは「1月」で補完するものとします。
「1月」で補完する関数を以下の通り定義しておきます。
def add_month(x):
if "月" not in x:
x += "1月"
return x
次に、現在時刻を基準に築年数の月数を返す関数(culc_age)を定義します。
from dateutil import relativedelta as rdelta
import datetime
def culc_age(target,dt_now):
year, month = target.split("年")
#print(year,month)
month = month.split("月")[0]
d1 = datetime.date(int(year),int(month),1)
d2 = datetime.date(dt_now.year,dt_now.month,dt_now.day)
rd = rdelta.relativedelta(d2,d1)
age = (rd.years * 12) + rd.months
return int(age)
culc_ageメソッドに築年数のデータ値と現在時刻を与えることで月数を返してくれます。
築年数には「1980年7月」のようなデータなので、split("年")で年と月に分割してdatetime型に変換します。
また、dateutilのrdeltaメソッドを使って現在時刻との差をとって月数を計算します。
それでは、「築年数」から月数を計算して新しく「築年月数」項目を追加します。
まず、「月」がないデータがあるので、欠損している場合は「1月」で補完し、そのあと「築年数」から「築年月数」を計算して列「築年月数」を追加します。
#月がないデータがあるので、欠損している場合は「1月」で補完する。 df['築年数'] = df['築年数'].apply(lambda x: add_month(x)) #築年数から月数の列を追加 dt_now = datetime.datetime.now() df['築年月数'] = df['築年数'].apply(lambda x: culc_age(x, dt_now))
上記を実行してdf.head()を実行すると以下のように「築年月数」が追加されます。

価格を「文字列」から「数値」(万単位)に変換する
最初にデータ型を確認した通り、「価格」のデータ型がobject型になっているため数値型に変換します。
単位は「万円」とします。
また、「価格」列のデータをよ~くチェックすると、「**万円」だけでなく稀に「1億6700万円」のように「億」が存在する値があるのですべての値を単位が「万円の数値」に統一するメソッドを作ります。
def conver_val(x):
if len(re.split('[万億]', x)) == 2:
value = re.split('[万億]', x)[0]
elif len(re.split('[万億]', x)) == 3:
value = re.split('[億万]', x)[0] + re.split('[億万]', x)[1]
return int(value)
上記メソッドを利用して新しい項目「価格(万円)」を追加します。
# 文字列を複数文字で split df['価格(万円)'] = df['価格'].apply(lambda x: conver_val(x))
df.head()で確認すると、以下のように「価格(万円)」の列(int型)が追加されます。

面積、バルコニーの広さを数値に変換する
つづいて、「面積、バルコニーの広さ」がobject型になっているので両方ともfloat型に変換します。
また、バルコニーは「-」の値があるので数字の「0」に置き換えます。
# 文字列を複数文字で split
df['面積'] = df['面積'].apply(lambda x: float(re.split('m', x)[0]))
df['バルコニーの広さ'] = df['バルコニーの広さ'].apply(lambda x: re.split('m', x)[0])
df['バルコニーの広さ'] = df['バルコニーの広さ'].apply(lambda x: x.replace("-","0"))
# 価格、面積、バルコニーデータを数値型に変換
import numpy as np
df['バルコニーの広さ'] = df['バルコニーの広さ'].astype(np.float)
ここで、df.info()で各列のデータ型を確認しておきましょう。
面積とバルコニーの広さが「float64」になっていればOKです。
<class 'pandas.core.frame.DataFrame'> Int64Index: 6311 entries, 0 to 6310 Data columns (total 10 columns): 物件名 6311 non-null object 住所 6311 non-null object 最寄り駅 6311 non-null object 築年数 6311 non-null object 価格 6311 non-null object 間取り 6311 non-null object 面積 6311 non-null float64 バルコニーの広さ 6311 non-null float64 築年月数 6311 non-null int64 価格(万円) 6311 non-null int64 dtypes: float64(2), int64(2), object(6) memory usage: 542.4+ KB
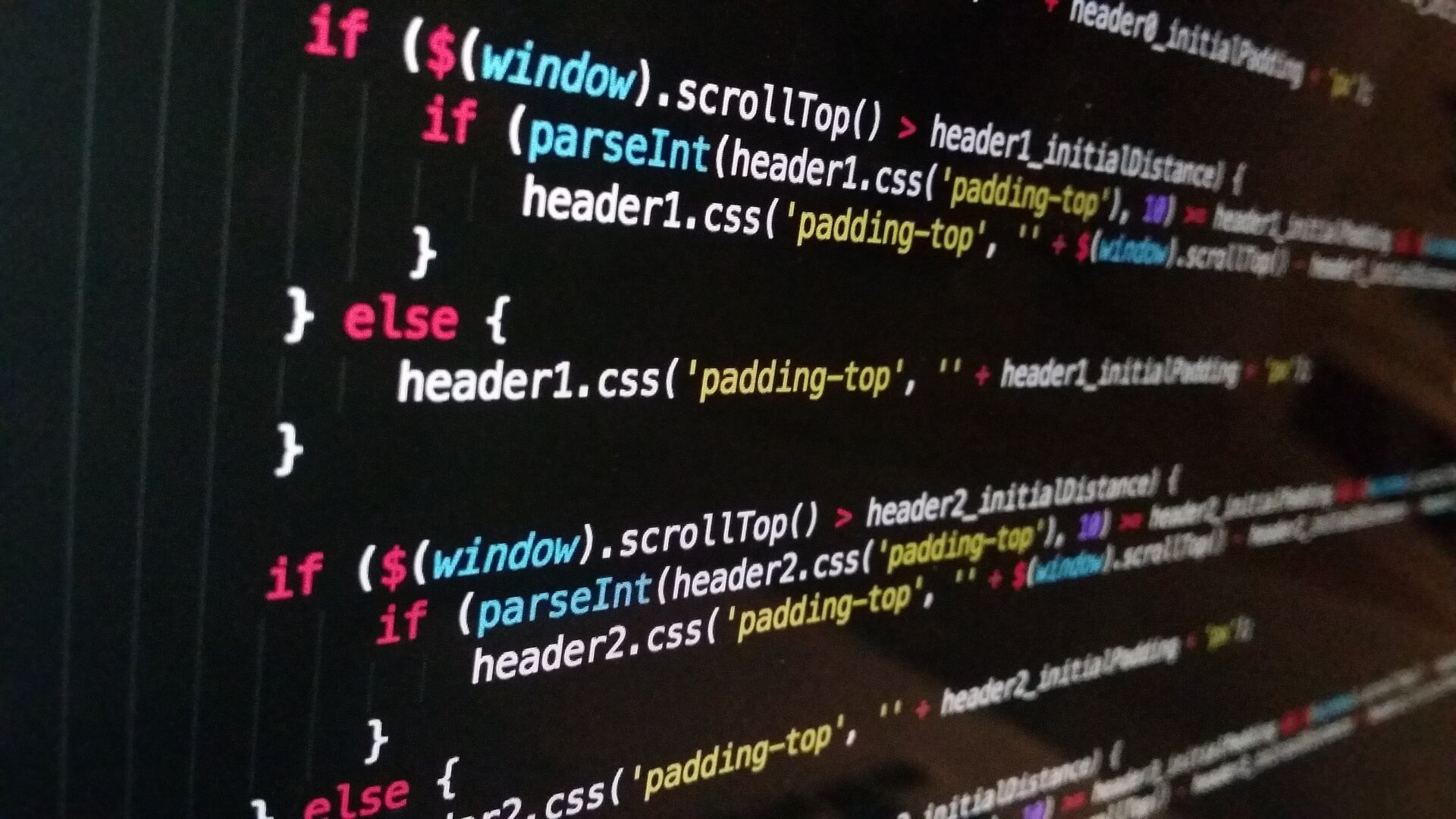
「不動産単価(万/平米)」欄を新設する
不動産の価格は広さによって変動するので、価格を基準に他の項目(例えば駅からどのくらい近いか?)と比較しても正しい分析ができないので、共通した指標が欲しいところです。
そこで、1平米あたりの単価(万円)を算出しておくことでデータ分析を行う際に単価基準で他の項目と比較分析することができます。
1平米あたりの単価は、単純に価格を平米数で割ればよいので以下コードで「不動産単価(万/平米)」列を新設します。
また、値を数値にするためint型に変換します。
df['不動産単価(万/平米)'] =round((df['価格(万円)'] / df['面積']),0) df['不動産単価(万/平米)'] = df['不動産単価(万/平米)'].round().astype(int)
df.head()で確認すると、以下の通り「不動産単価(万/平米)」列が追加されていることが確認できます。
間取りから「部屋数」欄を作成する
続いて、「間取り」の情報を何かを基準に数値データに変換したいところです。
間取りのデータ種類を確認してみます。
df['間取り'].unique()
array(['2LDK', 'ワンルーム', '3LDK', '3DK', '2DK', '2LDK+S(納戸)', '2DK+S(納戸)',
'1LDK', '3LDK+S(納戸)', '1LDK+S(納戸)', '4LDK', '4LDK+S(納戸)',
'1LDK+2S(納戸)', '1K', '5LK', '4DK', '5LDKK', '2LK', '2DKK+S(納戸)',
'5DK', '2K', '3K+S(納戸)', '3K', '3DK+S(納戸)', '1DK+S(納戸)', '1DK',
'5LDK', '1DK+2S(納戸)', '3LK', '2LDK+2S(納戸)', '3LDK+3S(納戸)',
'3LDK+2S(納戸)', '1ワンルーム'], dtype=object)
上記の通り、基本的には「**LDK、**DK」となっているので最初の数値を利用すれば部屋数に変換できそうです。
ただし、2つだけ例外があります。
「1ワンルーム、ワンルーム」という値があるので、これを「1RM」に変換します。
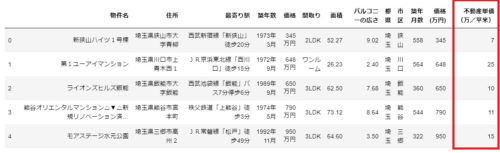
その後、re.search('[0-9]+', x)で数値の部分を取り出してInt型に変換して新しい列「部屋数」として追加します。
df['間取り'] = df['間取り'].str.replace('1ワンルーム', '1RM')
df['間取り'] = df['間取り'].str.replace('ワンルーム', '1RM')
df['部屋数'] = df['間取り'].apply(lambda x: int(re.search('[0-9]+', x).group(0)))
df.head()で確認すると、以下の通り「部屋数」の列が追加されます。
最寄り駅から「路線」、「駅名」、「手段」、「時間」に分ける
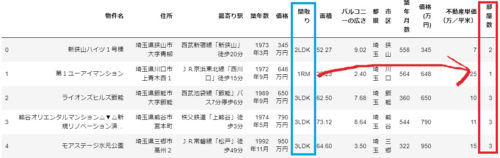
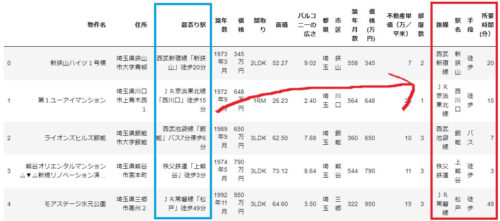
最後に、「最寄り駅」の列データを「路線、駅名、手段、時間」に分割します。
最寄り駅のデータを見ると「JR常磐線「松戸」徒歩49分」のような情報が格納されているので、うまくやれば「路線、駅名、手段、時間」に分割できそうです。
ただし、例外としてバスの情報が入っているデータは「JR京浜東北線「大宮」バス14分停歩1分」のように「停歩」の情報がありますが、今回は単純化するためにバスの停歩情報は除外します。
では、以下のコードで最寄り駅のデータを分割します。
df['路線'] = df['最寄り駅'].apply(lambda x: x.split('「')[0])
df['駅名'] = df['最寄り駅'].apply(lambda x: x.split('「')[1].split('」')[0])
df['手段'] = df['最寄り駅'].apply(lambda x: re.split(r'[0-9]+', x.split('「')[1].split('」')[1])[0])
df['所要時間(分)'] = df['最寄り駅'].apply(lambda x: int(re.search('[0-9]+', x.split('「')[1].split('」')[1]).group(0)))
df.head()で確認すると、以下の通りデータが分割できていることが確認できます。
以上でデータの前処理は完了です。
ここまでの前処理したデータを以下のコードでcsvに保存しておきましょう。
# 修正後のデータを保存
df.to_csv('data/suumo_bukken_mod.csv', sep = ',',encoding='utf-8-sig')
以上、不動産データ分析事例【pythonデータ前処理編】でした。
本記事の内容は、以下のサイトを参考にさせていただきました。
次回の記事では、前処理したデータを元にいろんな角度で不動産価格の分析を行っていきたいと思います。