こんにちは。sinyです。
本記事では、pythonを用いた不動産データ分析事例として、不動産 SUUMOサイトから中古の不動産情報をスクレイピングで取得する方法を解説します。
とても簡単ですので、スクレイピング初心者の方はぜひチャレンジしてみてください。
スクレイピングした後、データの前処理→データ分析を行いますが、スクレイピング以降はまた別記事で紹介します。

スクレイピング対象
不動産のデータ分析として都内23区を対象としたブログサイト等をよく見ますので、ここでは埼玉県全域の中古不動産情報をターゲットにしたいと思います。
スクレイピング対象のURLは以下の手順で取得します。
- 不動産 SUUMOサイトにアクセス→【中古マンション】→【埼玉県】→【市区郡にチェック】のすべてにチェック→【この条件で絞り込む】で検索
- ブラウザのURLをコピーしてurl変数にセット。
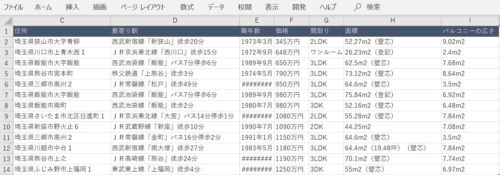
取得する情報は以下とします。(下図例の赤枠の項目)
- 物件名/住所/最寄駅/築年数/価格/間取り/面積/バルコニーの広さ

ソースコードはJupyternotebook形式でGithubに公開していますので、必要に応じてご利用ください。
ソースコードの解説
まず最初に必要なモジュールをインポートします。
今回はBeautifulSoupを使ってスクレイピングを行います。
import requests from bs4 import BeautifulSoup import time import pandas as pd import re
先ほど取得した検索対象のURLをurl変数にセットして、requests.getメソッドでHTMLを取得した後、BeautifulSoupで内容を解析しsoup変数に格納します。
# SUUMO 中古マンション 不動産情報 埼玉県全域 url = 'https://suumo.jp/jj/bukken/ichiran/JJ010FJ001/?ar=030&bs=011&ta=11&jspIdFlg=patternShikugun&sc=11102&sc=11103&sc=11104&sc=11105&sc=11106&sc=11107&sc=11108&sc=11109&sc=11110&sc=11201&sc=11202&sc=11203&sc=11206&sc=11208&sc=11209&sc=11210&sc=11211&sc=11212&sc=11214&sc=11215&sc=11217&sc=11218&sc=11219&sc=11221&sc=11222&sc=11223&sc=11224&sc=11225&sc=11227&sc=11228&sc=11229&sc=11230&sc=11231&sc=11232&sc=11233&sc=11234&sc=11235&sc=11237&sc=11238&sc=11239&sc=11240&sc=11241&sc=11243&sc=11245&sc=11246&sc=11300&sc=11320&sc=11340&sc=11440&sc=11460&kb=1&kt=9999999&mb=0&mt=9999999&ekTjCd=&ekTjNm=&tj=0&cnb=0&cn=9999999' result = requests.get(url) c = result.content soup = BeautifulSoup(c, "html.parser")
次に、pagination pagination_set-navクラスに定義されている検索結果のページ数を取得します。
# ページ数を取得
body = soup.find("body")
pages = body.find_all("div", {'class':'pagination pagination_set-nav'})
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
num_pages = int(pages_split[0].split('>')[-1])
print("ページ数=",num_pages)
次に検索ページ数分のURLをurls変数にリストとして生成します。
このURLをループで回して全ページ分の不動産情報を収集していきます。
# 全てのページのURLを作成
# urlを入れる箱(リスト)を設定
urls = []
# 1ページ目を格納
urls.append(url)
# 2ページ目以降を格納
for i in range(num_pages-1):
pg = str(i+2)
url_page = url + '&pn=' + pg
urls.append(url_page)
以下がメイン処理です。
各dottable dottable--cassetteクラス内に不動産の情報が格納されているため、ループ処理を回して不動産情報をすべて取得します。
data = []
for url in urls:
print(url)
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
summary = soup.find("div",{'id':'js-bukkenList'})
cassetteitems = summary.find_all("div",{'class':'dottable dottable--cassette'})
for cas in cassetteitems:
try:
# 情報取得用の箱を準備します。
subtitle = '' # 物件名
location = '' # 住所
station = '' # 最寄駅(リスト)
yrs = '' # 築年数
value = '' # 価格
floor_plan = '' # 間取り
area = 0 # 面積
balcony = 0 #バルコニーの広さ
thumb = '' #物件のURL
# 物件名
subtitle = cas.find_all("dd", "dottable-vm")[0].string
print(subtitle)
# 住所
location = cas.find_all("dd")[2].string
# 最寄駅
station = cas.find_all("dd")[3].string
# 築年数
yrs = cas.find_all("table", class_="dottable-fix")[1].select("dd")[1].string
#価格
value = cas.find_all("span", class_="dottable-value")[0].string
# 間取り
floor_plan = cas.find("table", "dottable-fix").select("dd")[1].string
#面積
area = cas.find("table", "dottable-fix").select("dd")[0].text
#バルコニーの広さ
balcony = cas.find_all("table", "dottable-fix")[1].select("dd")[0].text
data.append([subtitle, location, station, yrs, value, floor_plan, area, balcony])
time.sleep(1) # スクレイピングする際の礼儀として、1秒待ちましょう
ターゲットとなる情報「物件名/住所/最寄駅/築年数/価格/間取り/面積/バルコニーの広さ」は以下の部分で取得しています。
# 物件名
subtitle = cas.find_all("dd", "dottable-vm")[0].string
# 住所
location = cas.find_all("dd")[2].string
# 最寄駅
station = cas.find_all("dd")[3].string
# 築年数
yrs = cas.find_all("table", class_="dottable-fix")[1].select("dd")[1].string
#価格
value = cas.find_all("span", class_="dottable-value")[0].string
# 間取り
floor_plan = cas.find("table", "dottable-fix").select("dd")[1].string
#面積
area = cas.find("table", "dottable-fix").select("dd")[0].text
#バルコニーの広さ
balcony = cas.find_all("table", "dottable-fix")[1].select("dd")[0].text
1物件の情報をすべて取得したらdata変数に追加します。
data.append([subtitle, location, station, yrs, value, floor_plan, area, balcony])
礼儀として、1ページ分の情報を取得したら1秒待機させます。
time.sleep(1)
最後に収集した不動産データ(data)をpandasを使ってcsvファイルに出力します。
df = pd.DataFrame(data, columns=['物件名','住所','最寄り駅','築年数', '価格','間取り','面積','バルコニーの広さ'])
# csvファイルとして保存
df.to_csv('data/suumo_bukken.csv', sep = ',',encoding='utf-8-sig')
文字化け対策でエンコードにutf-8-sigを指定しています。
以上で、以下のような埼玉県全域の中古マンション情報が収集できす。






![ドロップダウン 選択時に画面を切り替える方法[PowerApps]](https://sinyblog.com/wp/wp-content/uploads/2020/06/employee-3005501_1920-300x300.jpg)







