こんにちは。sinyです。
「テキスト形式で保存されたPDFから文字情報を自動で抽出したい!」ということで、色々調べた結果、pdfminerというPythonライブラリーが使えそうだったので実際に試してみました。
気になった方はぜひチェックいただけたら幸いです。
教材の紹介動画です。
pdfminerとは?
pdfminerとはPDFデータ解析をするためのPytnonのライブラリーでだれでも無料で利用できます。
色々調べたところ、Pyhonのバージョンによって以下のようにモジュール名称が微妙に違うようです。
pdfminerの種類
pdfminer / python2.xx系
pdfminer3k / python3.xx系
pdfminer.six / python2/3系共通
pdfminer3k / python3.xx系
pdfminer.six / python2/3系共通
現状だと、Python3がメジャーなので「pdfminer3k or pdfminer.six」のどちらかでしょうかね。
ただ、現在でもアップデートされているのが「pdfminer.six」のようなので今回はpdfminer.sixを使ってみました。
ただ、現在でもアップデートされているのが「pdfminer.six」のようなので今回はpdfminer.sixを使ってみました。
pdfminer.sixのGITサイト

PDF→Excel変換のフロー
まず、今回お試しで開発したPDF→Excel変換アプリの全体フローです。
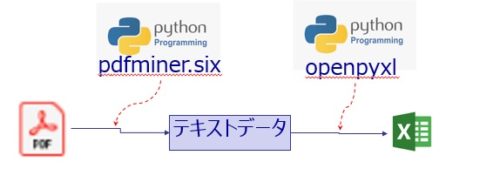
非常にシンプルですが、以下のような流れでPDFをExcel化します。
全体フロー
①WordやExcel等からPDFとして保存された請求書データを取り込む。
②pythonのpdfminer.sixを使ってPDFデータからテキスト情報を抽出
③pythonのopenpyxlを使って抽出したテキストデータをExcelへ書き込む。
②pythonのpdfminer.sixを使ってPDFデータからテキスト情報を抽出
③pythonのopenpyxlを使って抽出したテキストデータをExcelへ書き込む。
Djangoを使って実際に上記処理フローをWEBアプリ化してみましたが、割と簡単にできました。
実際に作ったアプリのデモ動画はこちら。
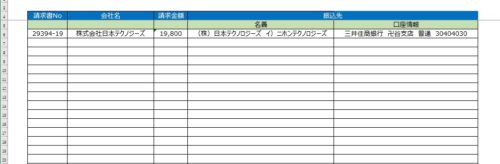
変換前の請求書PDFデータはこんな感じ。(架空の請求書です)

そして、Excel変換した後のデータがこんな感じ。
※請求No,会社名、請求金額、名称、口座情報がばっちり抽出できました。
※請求No,会社名、請求金額、名称、口座情報がばっちり抽出できました。
まとめ
まとめ
- pdfminerを使えばテキストベースのPDFデータは簡単にExcelデータ化できることが分かった。
- WordやExcel等を元にPDF変換して作成したPDFデータであれば、精度よくPDF→Excel変換を自動化できる。
→業務要件次第で有効活用できるケースはありそう。 - 今回作ったアプリはあくまでテキストベースのPDFデータしか対応していないので実用性があるかは微妙。
→請求書データは大抵スキャンデータとしてPDF化されているケースが多いとおもう。 - スキャンデータ(画像)からテキスト情報を抽出してExcelデータ化する(いわゆるOCR機能)ほうが実用的と思われるのでこちらの実現方法についても今後探っていこうと思う。
この記事が良かったと思う方はTwitterフォロー(shiny)とリツイート頂けると嬉しいです 😛