目次
こんにちは。sinyです。
本記事では、前回の下記記事で前処理した埼玉県全域の中古不動産情報に対して各種分析を行っています。

まずおさらいとして、前回作成した中古不動産データファイル(suumo_bukken_mod.csv)をpandasで読み込んで項目を確認しておきましょう。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
%matplotlib inline
df = pd.read_csv('data/suumo_bukken_mod.csv', index_col=0)
df.head()
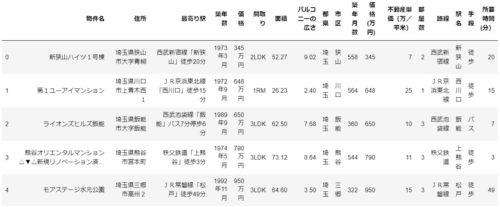
項目名として以下のデータがある状態になっています。
| 物件名 | 住所 | 最寄り駅 | 築年数 | 価格 | 間取り | 面積 | バルコニーの広さ | 都県 | 市区 | 築年月数 | 価格(万円) | 不動産単価(万/平米) | 部屋数 | 路線 | 駅名 | 手段 | 所要時間(分) |
|---|
事前準備
まず最初に、今回の目的である不動産価格に対するデータ分析を行うために分析の基準となる特徴量を1つ追加します。
ここでは、各中古不動産物件情報に対して、70㎡の面積に引き直した価格を「標準価格」として追加します。
計算方法は、「不動産単価(万円/㎡)×70」で求められます。
df['標準価格'] = df['不動産単価(万/平米)'] * 70 df.head()
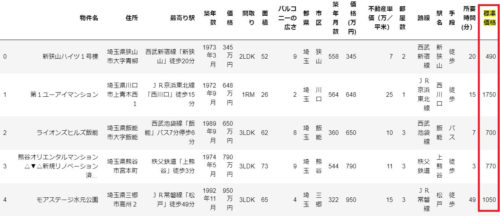
以下の通り、「70平米あたりの標準価格」が追加されます。
不動産価格と物件数の分布
まずは、中古不動産の価格と物件数の分布を確認してみます。
df['価格(万円)'].hist(bins=list(range(0,17000,200)), color='blue', alpha=0.5)
plt.title('埼玉県全域の中古不動産価格のヒストグラフ')
plt.xlabel('不動産価格(万円)')
plt.ylabel('個数')
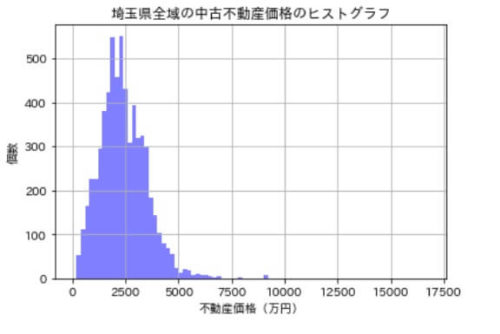
以下の通り、埼玉県の中古不動産のほとんどが2500万前後に集中していることがわかりますね。
ただし、実際には5000万以上クラスの物件もあるのですが数が少ないので上記グラフでは見分けがつきません。
こういう時はy軸に対して対数をとってあげます。
df['価格(万円)'].hist(bins=list(range(0,17000,200)), color='blue', alpha=0.5)
plt.title('埼玉県全域の中古不動産価格のヒストグラフ')
plt.xlabel('不動産価格(万円)')
plt.ylabel('個数')
plt.yscale('log')
以下の通り、7500万以上の物件がちょこちょこあるのが確認できますね。
1件だけ1億6000万くらすの物件があるようです(高っ!)

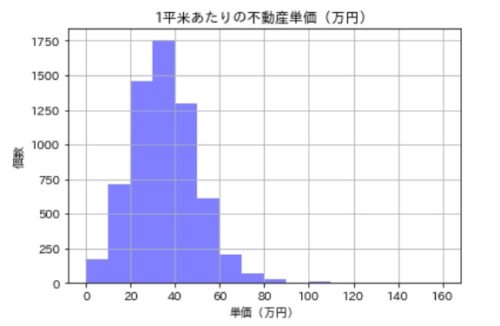
ついでに、価格単価:1平米あたりの価格(万)の物件数も見てみましょう。
df['不動産単価(万/平米)'].hist(bins=list(range(0,165,10)), color='blue', alpha=0.5)
plt.title('1平米あたりの不動産単価(万円)')
plt.xlabel('単価(万円)')
plt.ylabel('個数')
平均的には1平米あたり40万前後の物件が多いようですね。
市別の物件数
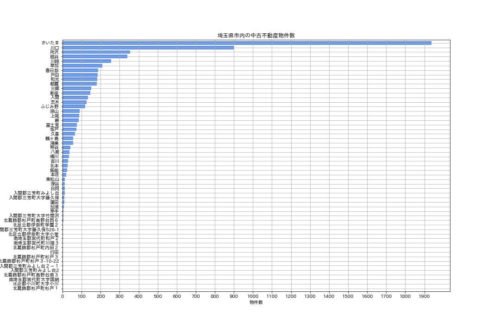
続いて、埼玉の市区町村別にどのくらいの物件数があるのか確認します。
grouped = df.groupby('市区')['物件名'].count().sort_values(ascending= True)
grouped.plot(kind='barh', fontsize=10, color='cornflowerblue', width=0.8, figsize=(15,10))
plt.title('埼玉県市内の中古不動産物件数')
plt.xlabel('物件数')
plt.xticks(np.arange(0, 2000, step=100))
plt.grid()
「さいたま、川口」の2つが突出して物件数が多いですね。
物件数と人口数の関係
では続いて、物件数と埼玉県の人口比率の関係性を見てみたいと思います。
埼玉県の人口データについては以下のHPの「概要版(エクセル:32KB) 市区町村別世帯数・人口」のデータを使います。
上記エクセルファイルから以下のようなcsvファイル(saitama_jinkou.csv)を作成しておきます。
| 区町村 | 人口 |
| さいたま | 1306919 |
| 西区 | 91724 |
| 北区 | 146099 |
| 大宮区 | 116882 |
| 見沼区 | 163948 |
| 中央区 | 101747 |
| 桜区 | 98290 |
| 浦和区 | 162777 |
| 南区 | 190487 |
| 緑区 | 124269 |
| 岩槻区 | 110696 |
| 川越 | 354301 |
| 熊谷 | 195177 |
まずは、saitama_jinkou.csvを読み込みます。
また、先ほど作成した市区町村別の物件数のデータ(grouped_df)をDataframeにしておきます。
df_pop = pd.read_csv('data/saitama_jinkou.csv', index_col=0)
# 市区町村別の物件数データ(grouped_df)を使う
grouped_df = pd.DataFrame(grouped)
grouped_df.head()
次に、埼玉県の人口データ(df_pop)と市区町村別の物件数データ(grouped_df)を共通である市区町村をキーにして結合させます。
# INDEX(市区町村データ)をキーにして人口データと結合。 df_grouped_pop = pd.concat([grouped_df, df_pop], axis=1, join='inner') #カラムを変更 df_grouped_pop.columns = ['物件数', '人口'] df_grouped_pop.head()
以下の通り、市区町村別の物件数と人工数のデータ(df_grouped_pop)ができあがりました。
あとは、df_grouped_popを使って散布図を描画してあげます。
#見ずらいので極端に数が多い埼玉を除外。
df_grouped_pop2 = df_grouped_pop[(df_grouped_pop['人口'] < 500000) & (df_grouped_pop['物件数'] < 900)]
plt.rcParams['figure.figsize'] = (25.0, 13.0)
plt.scatter(x=df_grouped_pop2['人口'], y=df_grouped_pop2['物件数'], color='cornflowerblue')
for x, y, z in zip(df_grouped_pop2['人口'], df_grouped_pop2['物件数'], df_grouped_pop2.index):
plt.annotate(str(z), ( x, y+5), size=15)
plt.title('人口と物件数の散布図')
plt.xlabel('人口の数',size=20)
plt.ylabel('物件の数',size=20)
plt.grid()
plt.savefig('人口と物件数の散布図.png')
散布図が非常に見ずらくなるので極端に数が多い埼玉を除外しています。

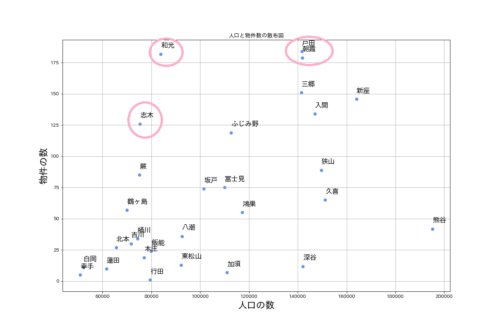
ちょっと見ずらいので、人口が20万人以下に絞ってみます。
項やってみると、基本的には人口が多いほど物件数が上がっていることが確認できますが、赤枠で囲んだ「和光、志木、戸田、朝霞」あたりは人口数はさほど多くなくても物件数が多いことがわかりますね。
きっと住みやすい街であったり、再開発が進んでいる地区である可能性が考えられると思います。
市区町村別の不動産価格
さらに深掘りしていきます。
今度は、市区町村別の不動産平均価格を見てみましょう。
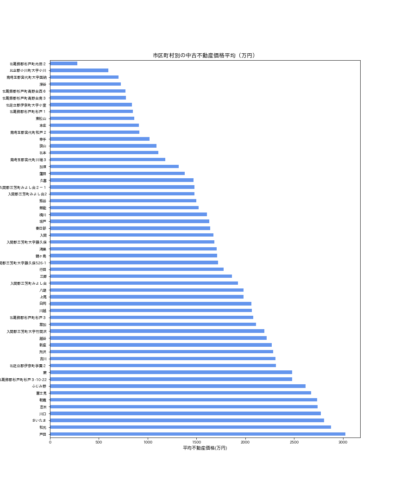
市区町村別の不動産平均価格を安い順に描画してみます。
grouped_price = df.groupby('市区')['価格(万円)'].mean().sort_values(ascending=False)
grouped_price.plot(kind='barh', fontsize=8, color='cornflowerblue', figsize=(12,10))
plt.title('市区町村別の中古不動産価格平均(万円)')
plt.xlabel('平均不動産価格(万円)')
plt.ylabel('市区町村名')
plt.savefig('市区町村別の中古不動産価格平均(万円)')
不動産の平均価格TOP5は「戸田、和光、さいたま、川口、志木、朝霞」となってますね。
さいたま、川口は人口が突出して多い地区なので平均価格も比例して高くなっているようですが、人口がさほど高くない「戸田、和光、志木、朝霞」の平均価格が高くなっています。
先ほど「和光、志木、戸田、朝霞」あたりは人口数はさほど多くなくても物件数が多いことがわかっていますので、「物件数が多い地区は平均価格も高くなる傾向がある」と言えるかもしれません。
築年数別の不動産単価(万/平米)
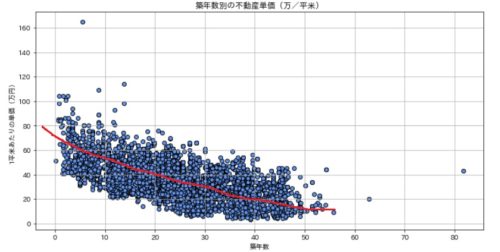
続いて、築年数が増えると不動産の1平米あたりの単価がどういった分布になるのか確認してみます。
plt.figure(figsize=(12,6))
plt.scatter(x=(df['築年月数']/12), y=df['不動産単価(万/平米)'],marker='o' ,edgecolors='black',color='cornflowerblue')
plt.title('築年数別の不動産単価(万/平米)')
plt.xlabel('築年数')
plt.ylabel('1平米あたりの単価(万円)')
ざっくりですが、以下の赤線のような傾向がみられますね。
具体的には、築年数が10年増えるごとに1平米あたりの単価が10万円安くなっている傾向がありそうです。
「中古の不動産を購入する際にどのくらいの築年数をターゲットにすればどのくらいの価格帯に抑えられるか?」の目安になりそうです。
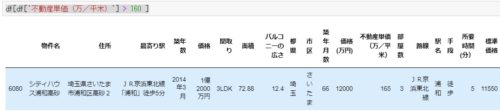
ここで、1件だけ築年数5年くらいで単価が160万を超えている物件があるのでどんな物件かチェックしてみます。
df[df['不動産単価(万/平米)'] > 160 ]
2014年築の浦和の「シティハウス浦和高砂」という埼玉県さいたま市浦和区の高層マンション物件ですね。
埼玉でもこんな高い中古物件があるんですね・・・
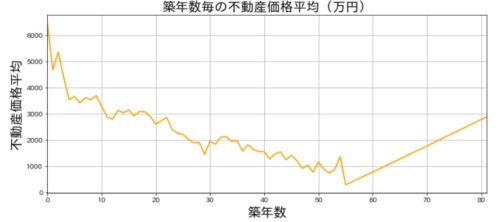
築年数毎の不動産価格平均(万円)
続いて、築年数毎の不動産価格平均(万円)をグラフ化してみます。
df['築年数'] = df['築年月数'] /12
df['築年数'] = df['築年数'].astype(np.int64)
df.groupby(by='築年数')['価格(万円)'].mean().plot(figsize=(12,5), linewidth=2, color="orange")
plt.title('築年数毎の不動産価格平均(万円)',size=20)
plt.xlabel('築年数',size=20)
plt.ylabel('不動産価格平均',size=20)
基本的には築年数が上がれば不動産価格が徐々に下がっていくことがわかります。
10年古くなると500万ほど価格が下がっていく傾向がありそうですね。
築年数毎の物件数
次に、築年数と物件数の分布も確認してみます。
df.groupby(by='築年数')['価格(万円)'].count().plot(figsize=(12,5), linewidth=2, color="orange")
plt.title('築年数毎の不動産物件数',size=20)
plt.xlabel('築年数',size=20)
plt.ylabel('不動産の物件数',size=20)
plt.grid()
築20~25年の物件数が一番おおいですね。
不動産業界に疎いのでよくわかりませんが、築50年以上の物件はほぼ0に近いので大体50年経過すると立て直すか、中古物件としては価値がなく売りに出ないのでしょうね。

市区別・築年数別の不動産単価(万/平米)の平均
さらに深掘りしてみましょう。
今度は、市区町村別+築年数別に不動産単価がどのような分布になっているか確認してみます。
#データ数の少ない築50年以降を除外
df_mod = df[df['築年数'] <= 50]
grouped_tanka_by_year_word = df_mod.groupby(by=['築年数','市区'])['不動産単価(万/平米)'].mean().unstack()
ser = grouped_tanka_by_year_word.mean().sort_values(ascending=False)
grouped_tanka_by_year_word = grouped_tanka_by_year_word[list(ser.index)]
#欠損値が多いので直前の値で補完。
grouped_tanka_by_year_word = grouped_tanka_by_year_word.fillna(method ='ffill')
grouped_tanka_by_year_word[grouped_tanka_by_year_word.index<=40].plot(figsize=(22,15), legend=True)
plt.title('市区別・築年数別の不動産単価(万/平米)の平均',fontsize=20)
plt.xlabel('築年数',size=20)
plt.ylabel('不動産価格平均',size=20)
plt.grid()
データが多すぎ&グラフが小さくてちょっとわからないですね・・・
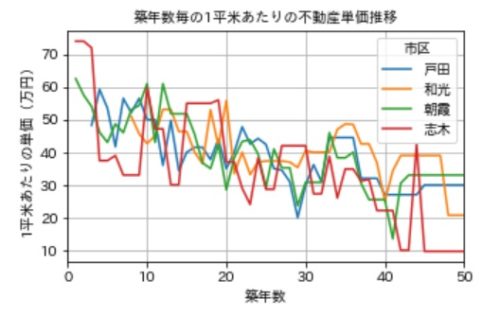
和光、志木、戸田、朝霞」あたりが人口数はさほど多くなくても物件数が多く、単価も高かった=人気がありそうな地区と仮定して、この4つの地区に絞ってデータを抽出してみます。
grouped_tanka_by_year_word[['戸田', '和光','朝霞','志木']].plot(figsize=(5,3), legend=True)
plt.title('築年数毎の1平米あたりの不動産単価推移',fontsize=10)
plt.xlabel('築年数',size=10)
plt.ylabel('1平米あたりの単価(万円)',size=10)
plt.grid()
結果は以下のようになりました。
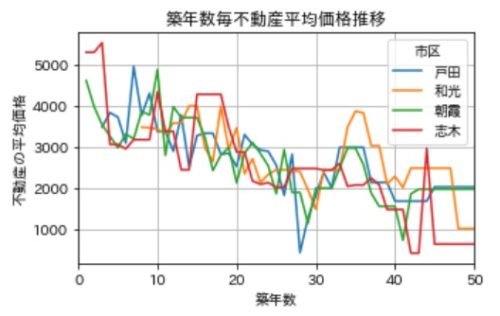
単価じゃなくて不動産の価格平均でみたいので、縦軸を不動産価格の平均にしてみます。
grouped_kakaku = df_mod.groupby(by=['築年数','市区'])['価格(万円)'].mean().unstack()
ser = grouped_kakaku.mean().sort_values(ascending=False)
grouped_kakaku = grouped_kakaku[list(ser.index)]
#欠損値が多いので直前の値で補完。
grouped_kakaku = grouped_kakaku.fillna(method ='ffill')
grouped_kakaku[['戸田', '和光','朝霞','志木']].plot(figsize=(5,3), legend=True)
plt.title('築年数毎不動産平均価格推移')
plt.xlabel('築年数')
plt.ylabel('不動産の平均価格')
plt.grid()
築年数が20後半~30年を超えてくると平均で2000万を割ってくる物件がちらほら出てくるようですね。
最寄駅からの時間による不動産単価
次は、最寄り駅からの時間で不動産単価がどのように変動するか確認してみます。
※なお、最寄駅から物件までの移動手段として「徒歩」の場合に絞ってグラフ化しています。
df_by_word = df_mod[df_mod['手段']=='徒歩'].groupby(by=['所要時間(分)','市区'])['不動産単価(万/平米)'].mean().unstack()
df_by_word = df_by_word[list(ser.index)]
df_by_word = df_by_word.fillna(method ='ffill')
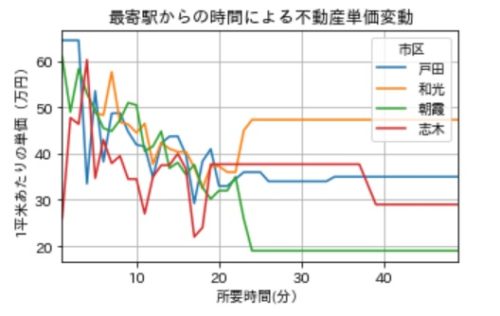
df_by_word[['戸田', '和光','朝霞','志木']].plot(figsize=(5,3), legend=True)
plt.title('最寄駅からの時間による不動産単価変動')
plt.xlabel('所要時間(分)')
plt.ylabel('1平米あたりの単価(万円)')
plt.grid()
例えば、70平米の広さで3000万円を切るラインを狙うなら単価は42万円程度を狙っていく必要がありますが、「和光、朝霞あたりだと築年数が15年前後でないとちょっと厳しい、戸田、志木あたりを狙えば築年数10年以内でも単価40万を切ってくる物件がありそう。」といったことがわかります。
K-means法でクラスタ分類
最後にk-meansを使って不動産データを5つのクラスタに分類し、「築年数と70平米あたりの不動産標準価格(万)」をグラフ化してみます。
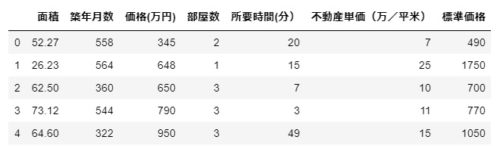
対象は数値データになっている「'面積','築年月数','価格(万円)', '部屋数', '所要時間(分)','不動産単価(万/平米)', '標準価格'」とします。
df_mod2 = df_mod[['面積','築年月数','価格(万円)', '部屋数', '所要時間(分)','不動産単価(万/平米)', '標準価格']] df_mod2.head()
各カラム毎に値の範囲が異なっているため、sklearnのStandardScalerを使って平均0、標準偏差1に正規化します。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(df_mod2) df_mod2_sc = pd.DataFrame(sc.transform(df_mod2), columns = df_mod2.columns) df_mod2_sc.head()
最後にsklearnのKMeansを使って5つのクラスタに自動分類してみます。
# KMeansの読み込み
from sklearn.cluster import KMeans
# 不動産データを5グループに分割
kcls = KMeans(n_clusters=5)
cst_group = kcls.fit_predict(df_mod2)
# クラスタIDを確認する
print(cst_group)
# 不動産データをクラスタIDごとに色付けし散布図で描画する
for i in range(5):
tmp = df_mod2[cst_group == i] # cst_group==iの箇所だけがTrue、その他がFalseになるのでTrueの行だけ取り出される。
plt.scatter(tmp['築年月数']/12, tmp['標準価格'], label=i)
plt.plot(figsize=(10,10))
plt.legend(fontsize=20,prop={'size':20})
plt.xlabel('築年数',size=20)
plt.ylabel('70平米あたりの不動産標準価格(万)',size=20)
plt.tick_params(labelsize=20)
plt.show()
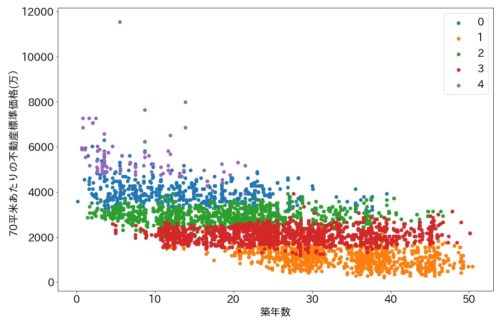
実行結果は以下の通りです。
5つのパターンにクラスタ分類されているのがわかります。
こんな風にクラスタ分類すると、どの価格帯の物件がどのくらいの築年数まで存在するか感覚的にわかるのでデータ特性を把握しやすいと思います。
以上、不動産データ分析事例【pythonデータ分析編】でした。
他にも様々な切り口でのデータ分析ができると思いますので、興味のある方はいろいろ試してみてみましょう。