こんにちは。sinyです。
この記事では、ディープラーニングの自然言語処理で用いられるSeq2Seq(sequence-to-sequence)の仕組みを使い、簡単な英和翻訳WEBアプリをDjangoで実装した際の内容についてまとめています。
アプリ実装までの内容が多いため、この記事では前編として、まずSeq2Seqの仕組みについてまとめています。
Seq2Seq(sequence-to-sequence)とは?
Seq2Seqとは、あるシーケンス(たとえば英語の文章)を受け取り、別のシーケンス(たとえば日本語の文章)に変換するモデルです。
例えば、以下のように英文を日本語に変換(翻訳)するようなタスクで利用することができます。
What's you name? --> あなたの名前は何ですか?
Seq2Seqは、翻訳以外にも以下のようなタスクで活用することができます。
- 文章の要約(長文の文章を要約する)
- 対話の生成(ある対話文章に対する応答を自動的に生成する)
Seq2Seqの仕組み
Seq2Seqでは通常RNN層(今回はLSTMを利用)を利用します。
また、入力を圧縮するencoderと出力を展開するdecoderからなるニューラルネットワークモデルを定義します。
以下はSeq2Seqの全体の概要図です。(英文を日本語に翻訳する例)
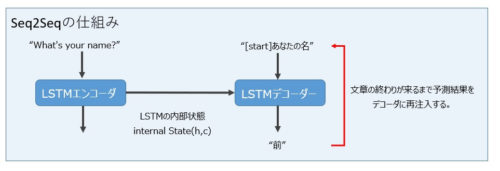
Encoder
Encoderには各時刻ごとに時系列データ(文章など)が入力されます。
EncoderのRNNレイヤ(上図ではLSTM)では、入力シーケンスを処理した結果として内部状態を返します。
EncoderのRNNの出力結果は破棄し、内部状態だけをDecoder側で利用します。
Decoder
Decoderでは、ターゲットとなるシーケンスの前の文字が与えられた場合、ターゲットシーケンスの次の文字を予測するように訓練します。
訓練では、Decoderへの入力を対話文における返答としてあらかじめ用意します。
ある時刻におけるDecoderの出力が次の時刻における入力に近づくように学習させます(このことを教師強制と言います)
Seq2Seqでは上記のような処理を行うことである時系列データが別の時系列データに変換(翻訳)されていきます。
今回の例では、英文が日本語に変換されるわけですね。
ポイントとしては、Decoderは初期状態としてEncoderからの状態ベクトル(文章全体の情報を表すベクトル)を利用します。
推論フェーズ
推論フェーズでは、以下の流れで処理を行います。
- 入力シーケンス(英文)を状態ベクトルに変換する。
- 学習済みLSTM層を利用したEncoderを使って入力データを与えて内部状態を取得する。
- 状態ベクトル(内部状態)と1文字のターゲットシーケンスをDecoderに入力して、次の文字に対する予測を生成する。
※今回の例では開始文字を意味するタブ「\t」をターゲットシーケンスの初期値として与えます。 - 次の文字をサンプリングします。
※argmaxで最大確率のトークン(日本語)を選択します。 - サンプリングされた単語(日本語)をターゲットシーケンス(正解となる日本語文)に追加します。
- Decoderで出力されたターゲットシーケンスと内部状態をDecoderの入力に与え、文字数の上限に達するかシーケンスの終了文字が生成されるまで処理を繰り返します。
今回はkerasの公式Githubのサンプルコード(lstm_seq2seq.py)を元に解説します。
上記で解説したSeq2Seqの仕組みを、KerasのLSTM層を使って構築した上記ソースコードの仕組みを整理するために図にまとめてみました。
まずは学習モデルです。
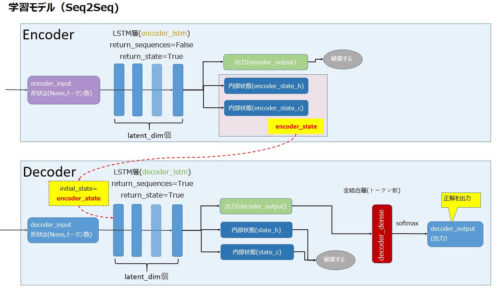
- EncoderのLSTM層の内部状態をDecoderに渡す必要があるためreturn_state=Trueを指定して内部状態を出力するようにします。
※LSTMでは内部状態として2つの値が返ってきます。(ちなみにGRUを利用する場合、内部状態は1つです) - Encoderの出力は破棄し、内部状態をDecoderの初期状態にセットします。
- Decoder側で生成された内部状態は不要なので破棄し、LSTM層の出力に対して全結合層を定義しSoftmaxで単語の確率を出力するモデルを定義します。
- encoder_input(英文)とdecoder_input(正解となる日本語文)を 入力データとして、decoder_output(予測値)を出力するモデルを定義します。
※注)latent_dimはLSTM層のユニット数を表す。
続いて推論モデルです。
推論モデルでは、学習済みのLSTM層(EncoderとDecoder)を利用します。
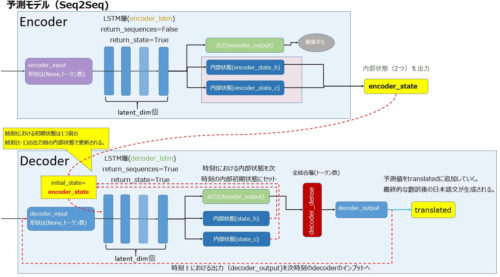
- Encoderモデルは、既存の学習済みLSTM層(encoder_lstm)を利用してencoder_input(英文)を入力、encoder_states(内部状態2つ)を出力します。
- Decoderモデルでは、既存の学習済みLSTM層(decoder_lstm)を使用し、初期状態にEncoderが出力した内部状態(encoder_states)を指定します。
- return_sequence=Trueとすることで、全ての時系列の出力が得られるようにします。
- 予測モデルのDecoderでは、時刻tにおけるdecoder_inputs(英文)と時刻t-1における内部状態(encoder_states)を入力し、処理結果の出力(decoder_output)と2つの内部状態(state_h、state_c)の両方を利用します。
※学習モデルではDecoderが出力した内部状態は破棄している点が推論モデルとなる。 - 時刻tにおけるDecoderが出力した予測値(encoder_output)と内部状態(state_h、state_c)を次時刻(t+1)のdecoderの入力にすることで次々と予測値を出力し、その結果をtranslated(最終結果を蓄積する変数)に蓄積していくことで日本語の文章が生成されていきます。
以上、Seq2Seqを実装する上で最低限抑えておきたい仕組みについての説明でした。
次回の記事では、上記の仕組みを利用して実際に英文を日本語に翻訳するSeq2Seqのコードを実装していきたいと思います。
最終的には、WEB画面上で英文を入力し、日本語に翻訳した結果を出力するWEBアプリをDjangoで実装していきます。