![時系列データ前処理手順の紹介[ディープラーニング+Python]](https://sinyblog.com/wp/wp-content/uploads/2018/12/developer-3461405_1920.png)
目次
こんにちは。sinyです。
ディープラーニングを学習し始めると、だいたい画像認識から始まり自然言語処理などを学びはじめたあたりからRNNやLSTM、GRUなどを学んでいくことになりますが、RNNあたりから時系列データを扱うことになると思います。
ただ、初心者にとってはこの時系列データの前処理あたりのやり方がいまいちわかりづらかったりして、挫折してしまう人も少なくないのではないかなと思います。
この記事では、ディープラーニングで時系列データを扱う場合に必要な前処理手順について、直感的で入門者にもわかりやすい方法をご紹介します。
この記事で紹介する手順以外にも様々な前処理のやり方がありますので、時系列データの前処理手順の1つとして参考にしていただければ幸いです。
時系列データ前処理の想定ケース
今回は、ある株価の時系列データを使って、11日分のデータを元に翌日の株価を予測するといったディープラーニングの学習モデルに前処理を行った株価のデータを入力させる例で説明します。
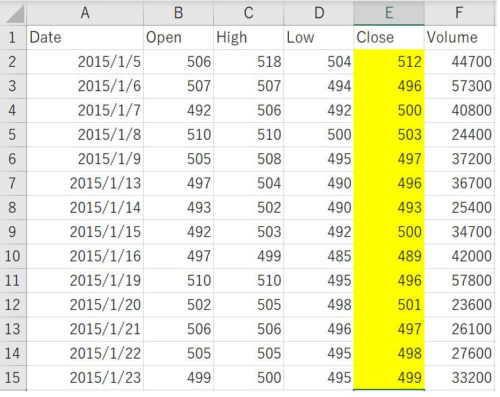
株価のデータは以下のサイトから2015~2018年分のデータをCSV形式でダウンロードして用意しました。
データとしては以下のようなCSVデータで、2015~2018年の株価データの「Close」列(株価の終値)を使うものとします。
データは1日ごとの株価の価格になっています。
時系列データの前処理の考え方
ディープラーニングで時系列データを用いる場合は、基本的にはWindowサイズと呼ばれる入力データとして与える時系列データの長さを定義します。
今回の例だと「過去11日分を入力データとして翌日のデータを予測する」というモデルなので、
過去11日+予測データ(1日分)→Windowサイズを12に設定します。
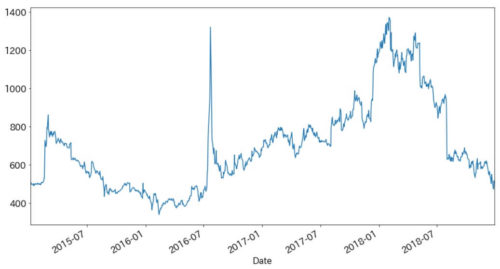
今回用意した2015~2018年の株価のデータをプロットすると以下のようなグラフになります。
Windowサイズ分のデータセットを開始位置を1点ずつずらしながら切り出して、学習モデルのインプットデータとする必要があります。
具体例を挙げると、以下のように12日分のデータを1セットとして開始位置を1点ずつずらしたデータを用意します。
・2015年1月5日~1月21日分のデータセット
・2015年1月6日~1月22日分のデータセット
・2015年1月7日~1月22日分のデータセット
※これを最後のデータまで繰り返します。

さらに、上記で作成した時系列データセットを学習データとテストデータに分けます。
今回は、2015~2017年のデータを学習データ、2018年のデータをテストデータにします。
時系列データの前処理手順
では、実際の前処理手順の例を記載します。
CSVデータをPandasで読み込む
まずはCSVデータをPandasで読み込みます。
ポイントは、CSVのData列をdatetime型で読み込み、Indexに指定します。
index_col='Date'
parse_dates=True
日付データ部分をIndexに指定してdatetime型にして読み込んでおくと、学習データとテストデータに分割する際の手順がとても簡単になります。
import pandas as pd
import matplotlib as plt
import japanize_matplotlib
import numpy as np
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv("6879_2015-2018.csv", encoding="shift-jis",
index_col='Date', parse_dates=True).fillna(method ='ffill')
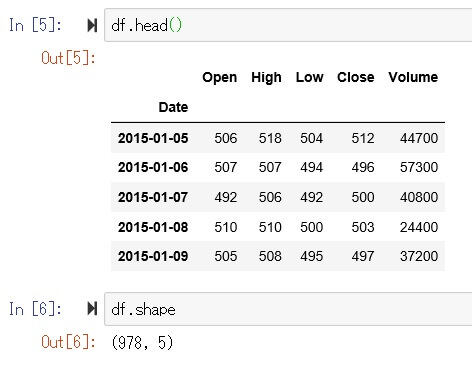
今回読み込んだデータは以下のような978行5列の株価のデータです。
データをトレーニングとテストに分割
2017年以前を学習用、2018年以降をテスト用データにするために読み込んだデータ(df)を分割します。
分割はPandasの機能を使って以下のように簡単に分割できます。
train = df['Close'][: '2017'] test = df['Close']['2018':]
これで分割は完了です。
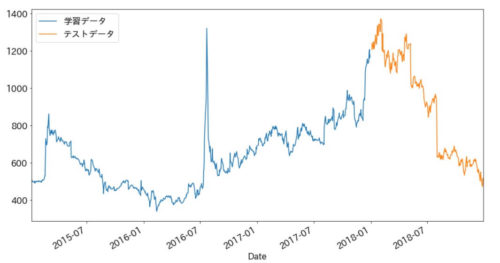
分割したデータをプロットしてみます。
ax = train.plot() test.plot(ax=ax) ax.legend(['学習データ', 'テストデータ'])
2018年前後でデータが分割できていることが確認できますね。
スケーリング
続いて、先ほど分割したtrainとtestデータ値が0~1の範囲に収まるように正規化を行います
pythonコードで直接正規化処理をコーディングしてもよいですが、sklearnのMinMaxScalerを使うと簡単に正規化できます。
sc = MinMaxScaler()
train_sc = pd.DataFrame(sc.fit_transform(train.values.reshape(-1,1)),
index=train.index, columns=['Scaled Data'])
test_sc = pd.DataFrame(sc.transform(test.values.reshape(-1,1)),
index=test.index, columns=['Scaled Data'])
上記のコードを実行するとPandas形式のままデータを正規化できるので便利です。
正規化後のデータをプロットして0~1に変換されているか確認してみます。
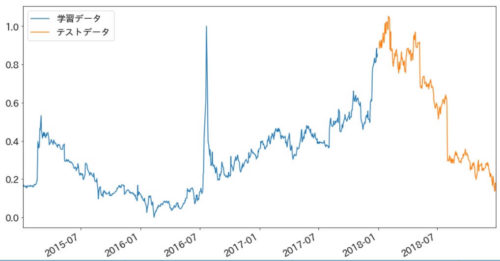
0~1に変換されていますね。
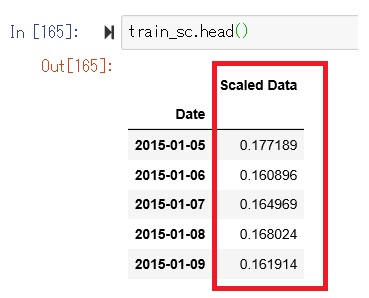
Pandasデータは以下のようにスケーリングしたデータ「Scaled Data」が生成されます。
Windowsサイズ分ずらしたデータセットを生成
ここが一番ややこしい部分ですが、Windowサイズ分(12)のデータセットを開始位置を1点ずつずらしながら切り出したインプットデータを生成します。
以下のイメージですね。
pandasでshitf関数というものを使うと簡単に上記データを生成できます。
使い方は簡単で、以下のコードを実行すると指定した列のデータをshift()の引数に指定した数分、列方向にずらしたデータセットを生成してくれます。
train_sc['Scaled Data'].shift(<ずらしたい数を指定>)
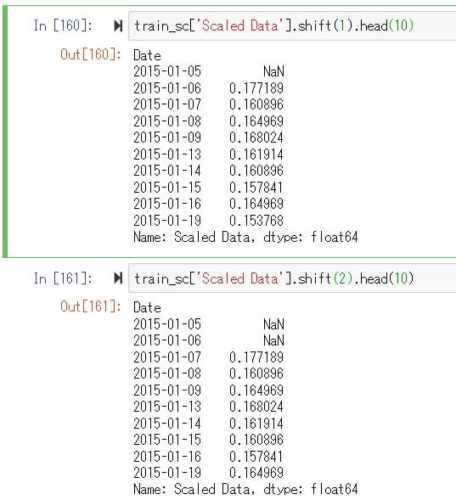
これを、Scaled Data'を軸にして1~12(Windowサーズ)ずつずらしたデータを生成してデータフレームの列に追加していくと1データ時点ずつずらしたWindowサイズ分(12個)のデータセットができあがります。
コードは以下の通りです。
window = 12
for i in range(1,window):
train_sc['shift_{}'.format(i)] = train_sc['Scaled Data'].shift(i)
test_sc['shift_{}'.format(i)] = test_sc['Scaled Data'].shift(i)
以下のように1行がWindowサイズ(12個)分の1個ずつずらしたデータセットが出来上がります。
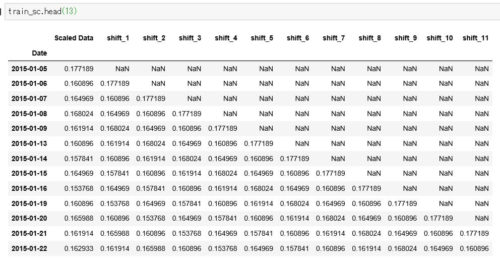
不要な時系列データの削除
上記の図を見ると分かる通り、データを1ずつずらしていくので、訓練データ、テストデータともに12行ずつ「Nan」を含んだデータセットが生成されていますが、これは不要なのでNanを含む行を削除します。
train_dna = train_sc.dropna() test_dna = test_sc.dropna()
時系列データを教師データと特徴量データに分ける
最後に、上記で生成したデータセットを入力と教師データ(正解データ)に分けます。
Y_train = train_dna[['Scaled Data']]
X_train = train_dna.drop('Scaled Data', axis=1)
Y_test = test_dna[['Scaled Data']]
X_test = test_dna.drop('Scaled Data', axis=1)
入力データ(shift_1~shift_10)と正解データ(Scaled Data)に分割されます。
以上で、時系列データの前処理は完了です。
後はこのデータセットを使ってディープラーニングの学習モデルのInputに入力すればOKです。
以上、時系列データ前処理手順の紹介[ディープラーニング+Python]でした。