
こんにちは。sinyです。
本記事では、Googleが2018年10月に発表した自然言語処理の手法であるBERTに関する情報を中心に2019年12月時点の状況についてまとめてみました。
そもそもBERTとは?
BERTとは「Bidirectional Encoder Representations from Transformers」の略称です。
BERT自体は、BERTという特別なモデルが存在するのではなく、以下の2つの手法を組み合わせることによって実現したものをBERTと呼んでいます。
- Attention
- Transformer
Attention
Attentionについて非常に簡素に言うと、複数の入力のうち「どの入力を重要視するか」を決定するニューラルネットワークの手法で、これまでのすべての入力を重み付きで直接参照して関連性の強い情報を抽出するような仕組みです。
Attentionの重要度はスカラ(一般に0.0~1.0の値)として計算されるので、Attentionの値を確認することで学習モデルが推論した結果計算過程の可視化(AIが判断した理由の可視化)にも用いられます。
※「判断理由にAttentionの値を利用することが果たして正しいのか?」という議論もあるようです。
なお、Attentionには大きく2種類(Self-Attention, SourceTarget-Attention)ありますが、NLP分野ではself-attentionを用いることが多いそうです。
【参考:Attentionの種類】
- input(query)とmemory(key, value)すべてが同じTensorを使うAttentionのこと。
- 言語の文法構造だったり、照応関係(it'sが示しているのはlawだよね)などを獲得するものに使われている。
- Self-Attentionは汎用的に使えるのでTransformerのEncoder、Decoderどちらでも使われる。
- 文章分類はSelf-Attentionのみで作ることが可能。
※各手法の詳細については下記サイトがわかりやすいため気になる方はご確認ください。
また、以前自身で内容を整理した資料をgithubにUPしていますのでこちらも参考にどうぞ。
Transformer
transfomrerはAttentionを組み込んだEncoder、Decoderになっています。
以下は、ネガポジを判定するtransformerモデルの概要図です。

transformerはそのままでは語順を捉えることができないため、位置情報(Positional Encoding)と呼ばれる成分と掛け合わせることで語順を表現します。
各トークンがどの位置にあるのかを表すための値(Positional Encoding) をEmbedding に足し合わせます。
PEは以下の計算式で求められます。
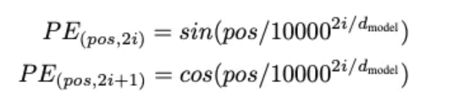
上記式のPEのかっこ内の「pos」は時刻(=その単語が何番目の単語か?)を表し、「2i, 2i+1」はEmbedding の何番目の次元かを表します。
もう少し分かりやすく説明すると、例えば下図のように文章の長さが256で300次元のデータがあるとします。
偶数(2i)と基数(2i+1)によって位置情報をembedingの出力(256*300)に足しこんできます。
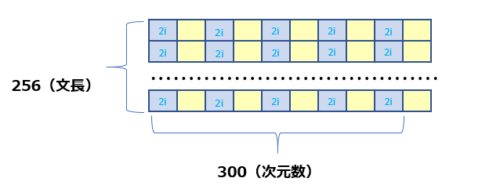
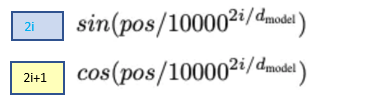
また、1つのAttentionではなく小さな複数のAttention(Mult-head Attention)を使い、複数のAttention計算を行うことで様々な観点で関係性を計算する仕組みになっているようです。
BERT
BERTはBidirectional Encoder Representations from Transformersということからもわかりますが、Transformerを24層積み重ねて、全て双方向で接続させたような構造になっています。

※1:入力された単語(seq_len)のうちマスクされた不明単語がvocab(全単語)のどれかをSoftMax関数で計算する。(マスクされた単語の前後何単語とは指定しない点がCBOWと違う)
※2:「連続的に存在する意味があって関係が深い文章」or 「全く関係がなく文脈のつながりがない2つの文章」のどちらかを判定する。
※3:最後のBertLayerの出力では文章中のある単語とその周辺単語の関係性をベースにその単語の意味にあった特徴ベクトルが生成される。
→例えば、銀行のbankと土手のbankは同じ単語でも前後の文章によって意味が異なってくる。
BERTでは、以下の2つのタスクを学習します。
- 文章の中でランダムに15%の単語をマスクし、その単語を当てる学習(Masked Language Model)
また、この部分を改善したモデルとしてALBERTといった新しいBERTの改善モデルが出てきています。
- BERTの学習済みモデルの最後の出力に1層追加するだけで自然言語処理タスクで最精度を出すことができる。(タスクやデータ数にもよると思いますが)
- 学習済みモデルを使ってファインチューニングができるので、少ない時間で学習が完了する。
- BERTを使う場合、前処理はほとんど必要ないようで、むしろ前処理しないほうが全体の構造を捉えることができてよいという意見もあるそうです。
※実際、前処理の有無で精度はほとんど変わらないようです。
※ただし、助詞などのストップワードは定義したほうがよいとのこと。 - バッチサイズを大きくしないと勾配が安定せず、学習が進みにくい傾向があるそうです。
- 学習率は低めに設定したほうがよい。
- 蒸留モデルは有効(40%のパラメータを減らして97%の精度を維持)
※ただし、蒸留は難しいので素人はあまり手を出さないほうが良い。
自然言語処理の精度評価の1つとしてGLUEという指標が用いられています。
GLUEは様々なタスクのデータセットに対して精度を評価してスコアを計算しているようです。
例えば以下のようなデータセットが含まれています。
・2つの質問が同じ意味か?
・質問応答でただし答えを含んでいるか?
・映画の感情分析でネガティブポジティブを判定
以下のサイトでは、GLUEによってスコアリングされた各手法のリーダーボードが公開されています。
今後について
先ほどのGLUEリーダーボードの上位を占めている学習モデルは、いずれもマルチタスクを1つのモデルで学習させるようなモデル(最終層でいろんなタスクに分かれている)になっているそうです。
最近「このようなモデルが次のトレンドになるのではないか?」という話を聞きました。
ただし、このようなモデルは学習に用いるデータセットの準備が非常に難しいというネックがあるようです。
日本語となるとさらにデータセットの用意のハードルが上がるので、なかなかすぐに…というわけにはいかなさそうですね。
あとは、分野ごとの学習データを使って学習したドメイン特化型BERTモデルのようなものが登場してくれば、より手軽に高精度のAIモデルを実装できる時代が来るのではないかなと思います。














