目次
Django · Data Backup · dumpdata / loaddata
運用中の Django アプリでは、定期バックアップは事故対策の必須要件です。Django には標準で dumpdata(JSON / XML 形式でデータをエクスポート)と loaddata(リストア)というコマンドが用意されており、DB エンジンに依存せず移行・復元ができます。本記事では基本的なバックアップ・リストア手順、特定モデルだけのバックアップ、cron で定期実行する運用パターンまで解説します。
本記事ではDjangoでModelデータの情報をCSV形式でバックアップする方法についてご紹介します。
user@sinyblog:~/article ❯ 01_section_1.mdモデルクラス
以下のような会計簿テーブル(モデルクラス)のデータ一覧情報をCSVファイルに出力する例で説明します。
from django.db import models
from datetime import datetime
class Category(models.Model):
class Meta:
#カテゴリ
verbose_name ="カテゴリ"
verbose_name_plural ="カテゴリ"
#カラム名の定義
category_name = models.CharField(max_length=255,unique=True)
def __str__(self):
return self.category_name
class Kakeibo(models.Model):
class Meta:
verbose_name ="家計簿"
verbose_name_plural ="家計簿"
#カラムの定義
date = models.DateField("日付",default=datetime.now)
category = models.ForeignKey(Category, on_delete = models.PROTECT, verbose_name="カテゴリ")
money = models.IntegerField("金額", help_text="単位は日本円")
quantity = models.IntegerField(verbose_name="数量",default=0)
memo = models.CharField(verbose_name="メモ", max_length=500)
def __str__(self):
return self.memo
user@sinyblog:~/article ❯ 02_section_2.mdバックアップコマンドの作成
今回は、Djangoのカスタムコマンドを使って家計簿テーブル情報をcsvデータファイルとしてバックアップ(出力)する処理を作ります。
以下のように、アプリケーションフォルダ(<app_name>)直下にmanagementフォルダを作成し、さらにその下にcommandsフォルダを作成します。
さらにそれぞれのフォルダ直下に__init__.pyファイルを空で作成します。
<app_name>
├─management
│ │ __init__.py
│ ├─commands
│ │ │ backup.py
│ │ │ __init__.py
commandsフォルダ直下にbackup.pyを作成し、ここにバックアップ処理を記述していきます。
import csv
import datetime
import os
from django.core.management.base import BaseCommand
from kakeibo.models import Kakeibo
class Command(BaseCommand):
def handle(self, *args, **kwargs):
date = datetime.date.today().strftime("%Y%m%d")
file_path = "backup/" + "kakeibo_" + date + ".csv"
os.makedirs("backup/", exist_ok=True)
with open(file_path, "w", newline="") as file:
writer = csv.writer(file)
header = [field.name for field in Kakeibo._meta.fields]
writer.writerow(header)
column_type = [field.__class__.__name__ for field in Kakeibo._meta.fields]
writer.writerow(column_type)
records = Kakeibo.objects.all()
for data in records:
writer.writerow([data.pk,
str(data.date),
data.category,
data.money,
data.quantity,
data.memo])
print("バックアップが完了しました")
Djangoでカスタムコマンドを実装するには以下の流れで実行したい処理を記述していきます。
- django.core.management.baseから BaseCommandをインポートする。
- BaseCommandを承継してCommandという名称のクラスを定義する
- handleメソッドを定義し、内部に実行したい処理を記述する。
今回は、handleメソッド内に以下の処理を定義しています。
date = datetime.date.today().strftime("%Y%m%d")
file_path = "backup/" + "kakeibo_" + date + ".csv"
os.makedirs("backup/", exist_ok=True)
date変数に現在日付をセットし、file_pathにはバックアップファイルのパスを設定しています。
os.makedirsでバックアップファイルの出力先ディレクトリを作成します。(exist_ok=Trueとすることでフォルダが存在していてもエラーを回避)
次のwith open以降ではKakeiboテーブルクラスから全データを取得して、csvのwriter.writerowメソッドでcsvファイルに1行ずつデータを追記してファイル出力させています。
with open(file_path, "w", newline="") as file:
writer = csv.writer(file)
header = [field.name for field in Kakeibo._meta.fields]
writer.writerow(header)
column_type = [field.__class__.__name__ for field in Kakeibo._meta.fields]
writer.writerow(column_type)
records = Kakeibo.objects.all()
for data in records:
writer.writerow([data.pk,
str(data.date),
data.category,
data.money,
data.quantity,
data.memo])
上記を実行すると、Djangoプロジェクト直下にbackupフォルダが生成され、kakeibo_20191229.csvのようなバックアップファイル(下図)が生成されます。
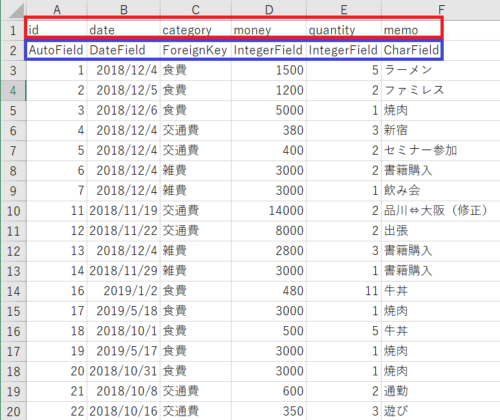
赤枠のテーブル列名は以下のコードで自動的に抽出しています。
header = [field.name for field in Kakeibo._meta.fields]
テーブルクラス名._meta.fieldsにアクセスすることでテーブルのメタ情報にアクセスすることができます。
さらにforループを回して.name属性を指定することで対象テーブルのカラム名を1つ1つ抽出することができます。
さらに、青枠はテーブルの各カラムのデータ型で以下のコードで自動的に抽出しています。
column_type = [field.__class__.__name__ for field in Kakeibo._meta.fields]これも先ほどと同様にテーブルのメタ情報にアクセスした後、今度は__class__.__name__を指定することでカラムのデータ型を抽出しています。
Djangoのshellモードでも以下の通りデータ型の情報が取得できることが確認できます。
(tutorial) C:\django\tutorial>python manage.py shell
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from kakeibo.models import Kakeibo
>>> column_type = [field.__class__.__name__ for field in Kakeibo._meta.fields]
>>> column_type
['AutoField', 'DateField', 'ForeignKey', 'IntegerField', 'IntegerField', 'CharField']
>>>
user@sinyblog:~/article ❯ 03_section_3.mdバックアップの実行
バックアップは「python manage.py backup」を実行するだけでOKです。
以上、「DjangoのModelデータをバックアップする方法」でした。