【Django × Pandas】QuerySet ⇆ DataFrame 双方向変換の実装パターン|集計・グラフ化・CSV 連携

目次
Django × Pandas · QuerySet ⇆ DataFrame 変換
集計レポート機能を Django で作るとき、DB から取り出したデータを Pandas の DataFrame に流し込んで処理したい場面は多いはず。逆に CSV を Pandas で前処理してから Django モデルに一括 INSERT したいケースもよくあります。本記事では、Django QuerySet ⇆ Pandas DataFrame の双方向変換 をシンプルな実装パターンで解説。集計 → グラフ化 → CSV 出力までの典型ワークフローも紹介します。
この記事では、DjangoでPandas(DataFrame)を活用する方法についてご紹介します。
user@sinyblog:~/article ❯ 01_django_pandas.mddjango-pandasを利用する。
下記リンクのdjango-pandasを利用すると、Djangoのモデルクラス(テーブルに格納されているデータ)を簡単にDataFrame形式に変換することができます。
まずは、基本的な使い方を具体例で説明します。
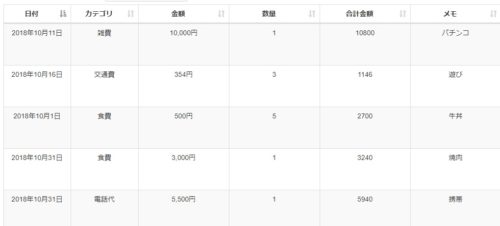
以下のような家計簿テーブルとカテゴリテーブルを例に説明します。
class Category(models.Model):
class Meta:
#カテゴリ
verbose_name ="カテゴリ"
verbose_name_plural ="カテゴリ"
#カラム名の定義
category_name = models.CharField(max_length=255,unique=True)
def __str__(self):
return self.category_name
class Kakeibo(models.Model):
class Meta:
verbose_name ="家計簿"
verbose_name_plural ="家計簿"
#カラムの定義
date = models.DateField("日付",default=datetime.now)
category = models.ForeignKey(Category, on_delete = models.PROTECT, verbose_name="カテゴリ")
money = models.IntegerField("金額", help_text="単位は日本円")
quantity = models.IntegerField(verbose_name="数量",default=0)
memo = models.CharField(verbose_name="メモ", max_length=500)
regist_date = models.DateTimeField(default=timezone.now)
def __str__(self):
return self.memo
この家計簿テーブルには以下のようなデータが登録されているとします。
普通に全レコードを取得する場合は以下のコードで取得できます。
from .models import Kakeibo
kakeibo_data = Kakeibo.objects.all()
kakeibo_dataはQuerySet形式のデータですが、django-pandasのread_frameを使うことで一発でDataFrame形式に変換することができます。
使い方はめちゃくちゃ簡単で以下の通り。
from django_pandas.io import read_frame
df = read_frame(kakeibo_data, fieldnames=['date', 'category', 'money', 'quantity', 'memo'])
read_frameの第1引数にQuerSetデータを指定し、fieldnamesに取得したいテーブルクラスのカラム(属性)をリスト形式で指定するだけです。
dfを表示してみると、以下の通りDataFrame形式に変換されていることが確認できます。
>>> df
date category money quantity memo
0 2018-12-04 食費 1500 5 ラーメン
1 2018-12-05 食費 1200 2 ファミレス
2 2018-12-06 食費 5000 1 焼肉
3 2018-12-04 交通費 380 3 新宿
4 2018-12-04 交通費 400 2 セミナー参加
5 2018-12-04 雑費 3000 2 書籍購入
6 2018-12-04 雑費 3000 1 飲み会
7 2018-11-19 交通費 14000 2 品川⇔大阪(修正)
8 2018-11-22 交通費 8000 2 出張
9 2018-12-04 雑費 2800 3 書籍購入
10 2018-11-29 雑費 3000 1 書籍購入
11 2019-01-02 食費 480 11 牛丼
12 2019-05-18 食費 3000 1 焼肉
13 2018-10-01 食費 500 5 牛丼
14 2019-05-17 食費 3000 1 焼肉
15 2018-10-31 食費 3000 1 焼肉
16 2018-10-08 交通費 600 2 通勤
17 2018-10-16 交通費 354 3 遊び
18 2018-10-11 雑費 10000 1 パチンコ
19 2018-10-31 電話代 5500 1 携帯
20 2018-11-30 電話代 6500 1 携帯
21 2018-12-31 電話代 7500 1 携帯
22 2019-01-31 電話代 5000 1 携帯
23 2018-12-08 食費 3000 1 食費
24 2018-12-09 食費 390 2 牛肉
25 2019-05-16 食費 500 3 吉牛
user@sinyblog:~/article ❯ 02_django_pandas.mddjango-pandasの応用事例

CSV生成用のボタンを定義する。
<form action='{% url 'kakeibo:export_kakeibo' %}' method='GET' enctype="multipart/form-data">
<div class="btn-group">
<input type="submit" class="btn btn-primary" value="csvファイル生成" data-toggle="tooltip" data-placement="right"data-html="true">
</div>
</form>
urls.pyの設定
CSV生成ボタンが押された際にCALLされるURLパターンを定義します。
例えば、アプリケーション配下のurls.pyのurlpatternsに以下のような定義を追加しておきます。
path('export_kakeibo/', views.export_kakeibo, name='export_kakeibo'),
また、プロジェクト直下のurls.pyには以下を追加してCSVが生成されるメディアファイルパスを定義しておきます。
from django.contrib import admin
from django.urls import path
from django.conf.urls import include, url
from django.conf import settings
from django.conf.urls.static import static #add
urlpatterns = [
path('admin/', admin.site.urls),
url('kakeibo/', include('kakeibo.urls')),
]
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)#add
ビューの設定
次にviews.pyの設定です。
CSV生成ボタンを押した際にCALLされるexport_kakeibo関数を定義します。
※エラー処理等は一切考慮していない簡単なコード例になってます。
from django.conf import settings
def export_kakeibo(request):
qs = Kakeibo.objects.all()
df = read_frame(qs, fieldnames=['date', 'category', 'money', 'quantity', 'memo'])
exp_path = settings.MEDIA_ROOT + "\\kakeibo_list.csv"
df.to_csv(exp_path, encoding='utf_8_sig',index=False)
return render(request, 'kakeibo/kakeibo_export.html')
django-pandasのread_frameでDataFrame形式に変換したデータ(qs)を、以下to_csvメソッドを使ってメディアファイルパスにcsv形式で保存しています。
df.to_csv(exp_path, encoding='utf_8_sig',index=False)
日本語文字化け対策のために「encoding='utf_8_sig'」、DataFrameのIndexを除外するために「index=False」を指定しています。
これで、メディアファイルパスにcsvファイルが生成されます。
settings.pyには以下のメディアファイルの設定をしておきます。
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
MEDIA_URL = '/media/'
テンプレートの設定
最後に、csvファイル生成ボタンを押した後に表示されるCSVダウンロード画面を定義します。
<div class="alert alert-success alert-dismissible" role="alert">
<a href="http://127.0.0.1:8000/media/kakeibo_list.csv">kakeibo_list.csv</a>
</div>
非常に簡素に作っていますが、これで以下のような画面が表示されてkakeibo_list.csvをクリックするとメディアディレクトリ上からcsvファイルをダウンロードできるようになります。

一旦メディアディレクトリにcsvを格納しているのが微妙(手間をかけている)な気がしますが、突貫で作ったのでご了承ください。
(ほんとはメモリ内で完結させられれば良いと思いますが・・・)
あと、pandas自体はフィルタリングや集計処理なんかも簡単にできるので、その辺の機能をうまく組み合わせればほしい情報だけを
csvに落とすなんてこともできると思います。
以上、django-pandasの基本操作と活用事例についてでした。
少しでも参考になれば幸いです。