こんにちは。sinyです。
ディープラーニングの勉強をちまちまと継続しており、学習済みCNNモデルの再利用方法について勉強しているのですが、
なかなか頭の中で整理ができないので、備忘録の意味も含めて要点をまとめてみました。
同じように勉強している方のお役に立てればうれしいです。
学習済みモデルから特徴抽出を行う方法
学習データ数が少ない場合の効率的な訓練方法として、学習済みモデルを利用する手法があります。
VGG、RestNet、Inceptionなど大量データを使って学習済みの公開されているモデルを再利用することで、短時間で精度の高いモデルを構築していくというアプローチです。
CNNの学習済みモデルには、「畳み込み+プーリング層」(以降、畳み込みベースと記載)と最後に「全結合層」がありますが、全結合層は除外して畳み込みベース部分を使ってデータを処理し特徴を抽出します。
抽出した特徴データをスタンドアローン(単独)の全結合層に投入して学習させるという方法(下図参照)です。
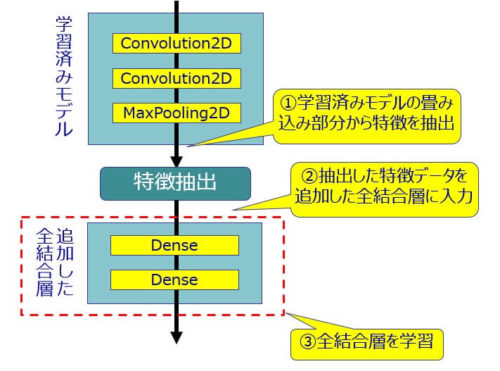
ポイント
- 学習済みモデルの分類機は基本的に利用しない。
⇒全結合層が学習した表現はそのモデルに特化したものなので、汎用的に使いまわせる可能性が低いため。 - 元のモデルと新しいデータセットの特徴が大きく異なる場合は畳み込みベース全体から特徴抽出するのはよくない。
⇒モデルの最初の方にあるいくつかの層から特徴抽出するのがよい
■モデルの最初の方の層には汎用的な特徴表現が格納されている(エッジ、色など)
■モデルの後ろの方には抽象的な特徴表現が格納されている(人の目、耳など) - 比較的計算コストが低いのでGPUなしでも学習できるケースが多い。
- データ拡張ができない。
既存モデルに全結合層を追加して全体を学習する方法
この方法は畳み込みベースに全結合層ネットワークを追加して、全体で学習する方法です。
最初の方法に比べると計算コストが高いので時間がかかりますが、データ拡張できるのでより精度の高いモデルを構築できる可能性が高いです。
学習済みモデルの畳み込みベースの層は、学習によって特徴表現が破壊されないように凍結しておく必要があります。

ポイント
- データ拡張ができる
⇒計算コストが高くなるのでGPU必須 - 学習済みモデルの特徴が失われないように学習前に畳み込みベースを凍結させる。
- この手法は畳み込みベースを拡張して最初から最後まですべての処理を入力データで処理する方法
- 訓練の対象になるのは追加した全結合層の重みだけ。
⇒畳み込みベースの重みは凍結しているので更新されない
ファインチューニングによる再利用の方法
最後にファインチューニングという手法があります。
これは、学習済みモデルの畳み込みベースを部分的に解凍して、追加した全結合層と同時に訓練を行うという手法です。
処理フロー概要
1.訓練済みモデル(畳み込みベース部分のみ)の最後に全結合層を追加する。
2.畳み込みベースを凍結する。
3.追加した全結合層を訓練する。
4.畳み込みベースの一部を解凍して重みが更新できる状態にする。
5.解凍した畳み込みベース層と追加した全結合層を同時に訓練する。
2.畳み込みベースを凍結する。
3.追加した全結合層を訓練する。
4.畳み込みベースの一部を解凍して重みが更新できる状態にする。
5.解凍した畳み込みベース層と追加した全結合層を同時に訓練する。
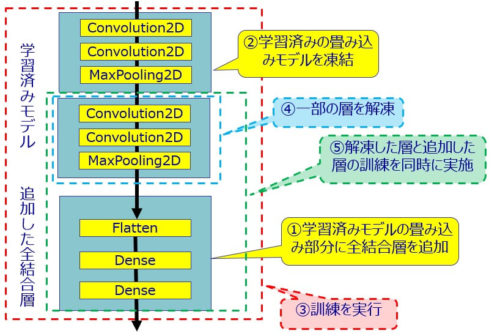
ポイント
- 必ず追加した全結合層を訓練した後に、畳み込みベースの一部を解凍して、再度全体を訓練する。
⇒全結合層の訓練をする前に全結合層を解凍して訓練させてしまうと、未学習の全結合層から逆伝搬で畳み込みベースへ伝わる誤差情報が大きすぎてもともと精度が高い畳み込みベースの特徴表現が破壊されてしまうため。 - ファインチューニングは既存モデルを有効活用しつつ、適度に既存モデルをチューニングして行くようなイメージ。
- ファインチューニングではかなり低めの学習率を利用するほうがよい。
⇒解凍した畳み込みベース層の変更の大きさを制限するため。
大きく変更されてしまうと学習済みのよい表現が破壊される可能性があるため。
以上、学習済みCNNモデルの再利用方法についてのまとめでした。
この記事が良かったと思う方はTwitterフォロー(shiny)とリツイート頂けると嬉しいです!