目次
- 1 user@sinyblog:~/article ❯ 01_compliance.mdスクレイピング前に確認すべき法令・倫理
- 2 user@sinyblog:~/article ❯ 02_target.md取得するデータと対象 URL
- 3 user@sinyblog:~/article ❯ 03_install.md必要なライブラリ
- 4 user@sinyblog:~/article ❯ 04_overview.md処理の全体フロー
- 5 user@sinyblog:~/article ❯ 05_pagination.md実装(1) 検索結果ページ数の取得
- 6 user@sinyblog:~/article ❯ 06_url_list.md実装(2) 全ページの URL を生成
- 7 user@sinyblog:~/article ❯ 07_extract.md実装(3) 物件情報の抽出ループ
- 8 user@sinyblog:~/article ❯ 08_csv.md実装(4) CSV への書き出し
- 9 user@sinyblog:~/article ❯ 09_result.md取得結果のサンプル
- 10 user@sinyblog:~/article ❯ 99_summary.mdまとめと次のステップ
Python × Web Scraping · 2026 Edition
不動産データ分析の入口として「自分で物件データを集めたい」と考える初学者は多いものの、いざ手を動かすと HTML 構造の読み解き・ループ設計・法令配慮 でつまずきがちです。本記事では Python の requests + BeautifulSoup で SUUMO の中古マンション情報(物件名・住所・最寄駅・築年数・価格・間取り・面積・バルコニー)を自動収集し、CSV に書き出すまでの完全手順を解説します。所要時間 30 分。

user@sinyblog:~/article ❯ 01_compliance.mdスクレイピング前に確認すべき法令・倫理
2024 年以降、Web スクレイピングを巡る議論は活発化しています。技術的に取得できることと、法的・倫理的に取得して良いことは別問題です。本記事のコードを実行する前に、必ず以下を確認してください。
- robots.txt の確認 —
https://suumo.jp/robots.txtを開き、対象パスがDisallowされていないか確認 - 利用規約の確認 — SUUMO の利用規約「禁止事項」項目で「自動収集ツールの使用」に関する記述を確認
- アクセス間隔の遵守 — 1 秒以上の間隔(本記事では
time.sleep(1))を守り、サーバーに負荷をかけない - 収集データの利用範囲 — 個人学習・分析の範囲を超えて再配布する場合は、著作権・データベース権の確認が必須
- アクセス頻度の自制 — 一度収集したデータは保存し、繰り返し同じ URL を叩かない
本記事の目的は Python のスクレイピング技術の学習 であり、収集したデータを商用利用したり再配布したりすることは想定していません。学習目的の範囲内で、節度を持って実行してください。
user@sinyblog:~/article ❯ 02_target.md取得するデータと対象 URL
不動産データ分析の題材としては都内 23 区が定番ですが、本記事ではあえて 埼玉県全域の中古マンション情報 をターゲットにします。市場規模が手頃で、ページ数も学習用に丁度よいスケールです。
取得する 8 項目は以下の通り。
- 物件名 / 住所 / 最寄駅 / 築年数
- 価格 / 間取り / 面積 / バルコニーの広さ
スクレイピング対象 URL は、SUUMO の検索結果ページから手動で取得します。
- SUUMO トップページ にアクセス
- 「中古マンション」→「埼玉県」→ 市区郡すべてにチェック → 「この条件で絞り込む」
- 表示された検索結果ページの URL をコピーして、後述の
url変数にセット

本記事のコード一式は GitHub にも公開しています。Jupyter Notebook 形式で動作確認できます。
user@sinyblog:~/article ❯ 03_install.md必要なライブラリ
本記事では requests で HTML を取得し、BeautifulSoup で解析します。データ整形には pandas を使用します。
pip install requests beautifulsoup4 pandasimport requests
from bs4 import BeautifulSoup
import time
import pandas as pd
import reuser@sinyblog:~/article ❯ 04_overview.md処理の全体フロー
実装は以下 4 ステップで進めます。
- 検索結果のページ数を取得 — pagination から最終ページ番号を抜き出す
- 全ページの URL リストを生成 — 1 ページ目の URL に
&pn=2,&pn=3... を付与 - 物件情報の抽出ループ — 各 URL を順に取得し、
dottable--cassetteクラスから 8 項目を抜き出す - CSV 書き出し — pandas の DataFrame に変換して
to_csv
user@sinyblog:~/article ❯ 05_pagination.md実装(1) 検索結果ページ数の取得
最初に対象 URL の HTML を取得し、BeautifulSoup でパース。pagination pagination_set-nav クラスから最終ページ番号を抽出します。
# SUUMO 中古マンション 不動産情報 埼玉県全域(URLは検索結果からコピーしたものに置換)
url = 'https://suumo.jp/jj/bukken/ichiran/JJ010FJ001/?ar=030&bs=011&ta=11&...'
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
# ページ数を取得
body = soup.find("body")
pages = body.find_all("div", {'class': 'pagination pagination_set-nav'})
pages_text = str(pages)
pages_split = pages_text.split('</a></li>\n</ol>')
num_pages = int(pages_split[0].split('>')[-1])
print("ページ数 =", num_pages)SUUMO の検索結果 URL はクエリパラメータが多く(市区郡コード sc=11102 等が並ぶ)、手動でブラウザからコピーするのが最も確実です。Python から検索フォームを叩く方法もありますが、本記事のスコープ外とします。
user@sinyblog:~/article ❯ 06_url_list.md実装(2) 全ページの URL を生成
取得した num_pages を使い、2 ページ目以降の URL を &pn=N 形式で組み立ててリストに格納します。
# 全ページの URL を作成
urls = []
# 1 ページ目
urls.append(url)
# 2 ページ目以降
for i in range(num_pages - 1):
pg = str(i + 2)
url_page = url + '&pn=' + pg
urls.append(url_page)user@sinyblog:~/article ❯ 07_extract.md実装(3) 物件情報の抽出ループ
本記事の核となる部分です。各 URL に対してリクエストし、dottable dottable--cassette クラスのカード要素から 8 項目を抜き出します。
data = []
for url in urls:
print(url)
result = requests.get(url)
c = result.content
soup = BeautifulSoup(c, "html.parser")
summary = soup.find("div", {'id': 'js-bukkenList'})
cassetteitems = summary.find_all("div", {'class': 'dottable dottable--cassette'})
for cas in cassetteitems:
try:
# 取得用の変数を初期化
subtitle = '' # 物件名
location = '' # 住所
station = '' # 最寄駅
yrs = '' # 築年数
value = '' # 価格
floor_plan = '' # 間取り
area = 0 # 面積
balcony = 0 # バルコニーの広さ
# 物件名
subtitle = cas.find_all("dd", "dottable-vm")[0].string
print(subtitle)
# 住所
location = cas.find_all("dd")[2].string
# 最寄駅
station = cas.find_all("dd")[3].string
# 築年数
yrs = cas.find_all("table", class_="dottable-fix")[1].select("dd")[1].string
# 価格
value = cas.find_all("span", class_="dottable-value")[0].string
# 間取り
floor_plan = cas.find("table", "dottable-fix").select("dd")[1].string
# 面積
area = cas.find("table", "dottable-fix").select("dd")[0].text
# バルコニーの広さ
balcony = cas.find_all("table", "dottable-fix")[1].select("dd")[0].text
data.append([subtitle, location, station, yrs, value, floor_plan, area, balcony])
except Exception as e:
print(f"skip: {e}")
continue
time.sleep(1) # マナーとして 1 秒待つtime.sleep(1) は必ず入れる
1 ページ取得するたびに 1 秒の間隔を空けます。これは技術的な要件ではなく 礼儀 です。スクレイピングはサーバーに負荷をかける行為なので、ループの最後に必ず入れてください。
本記事のコードは 2019 年の SUUMO HTML 構造を前提としています。サイト改修により dottable--cassette や js-bukkenList のクラス名・構造が変わると動かなくなります。実行時にエラーが出た場合は、ブラウザの開発者ツールで対象要素のクラス名を確認し、コードを調整してください。
user@sinyblog:~/article ❯ 08_csv.md実装(4) CSV への書き出し
収集した data を pandas の DataFrame に変換し、CSV ファイルとして保存します。
df = pd.DataFrame(
data,
columns=['物件名', '住所', '最寄り駅', '築年数', '価格', '間取り', '面積', 'バルコニーの広さ']
)
# CSV として保存(Excel で開く場合に文字化けしないよう utf-8-sig)
df.to_csv('data/suumo_bukken.csv', sep=',', encoding='utf-8-sig')utf-8-sig が無難
Windows の Excel で CSV を開くと、通常の utf-8 では日本語が文字化けします。BOM 付きの utf-8-sig を指定しておけば、Excel でもダブルクリック1発で正しく開けます。
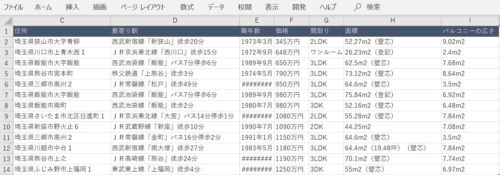
user@sinyblog:~/article ❯ 09_result.md取得結果のサンプル
上記のコードを実行すると、埼玉県全域の中古マンション情報が CSV に保存されます。出力イメージは以下のとおり。
user@sinyblog:~/article ❯ 99_summary.mdまとめと次のステップ
本記事のポイントは 3 つです。
- スクレイピングは法令・倫理を最優先。robots.txt と利用規約を必ず確認し、
time.sleep(1)でアクセス間隔を空ける - BeautifulSoup の
find_all+ クラス名指定で、対象サイトの構造に合わせて 8 項目を抽出 - pandas + utf-8-sigで Excel でも文字化けしない CSV を書き出す
収集したデータは「平均価格」「築年数別の価格分布」「駅徒歩時間との相関」など、様々な分析の素材になります。次回はこのデータを 前処理 → 統計分析 → 可視化 していく流れを紹介する予定です。