こんにちは。sinyです。
本記事はpythonのデータ前処理でよく使うpandasのメソッドをまとめた記事です。
よく使う重要コマンド
| 項目 | コマンド |
| 形状チェック | df.shape |
| データ型のチェック | df.dtypes |
| 欠損値のチェック |
df.isnull().any(axis=1) ※行方向 |
| 欠損値の数のチェック | df.isnull().sum(axis=1)※行方向 df.isnull().sum(axis=0)※列方向 |
| 欠損値の削除 | df.dropna() ※subset=['column1', 'column2']で複数カラムを指定できる。 |
| 欠損値の補完 | df.fillna(method='ffill')※直前の値で補完 df.fillna(method='bfill')※直後の値で補完 df.fillna(df.mean())※平均値で補完 |
| 統計量のチェック | df.describe() |
| 相関関係のチェック | df[['column1', 'column2']].corr() |
| 値の出現回数チェック | df['column'].value_counts(ascending=False, normalize=True)) ※normalizeをTrueにするとカウントを出現数の合計が1になるように正規化してくれる。 df['column'].value_counts(ascending=False, normalize=True)).indexとすると、Index部分(値の種類)だけ抽出 →逆に「.values」をつけると値(比率部分)だけを取得できる。 ※データ数の割合を円グラフ(plt.pie(x,y)にする場合などに便利) |
| 値の置換 | df.replace('置換したい文字列', '置換後の文字列')で置換可能。 |
| ユニーク値のチェック | df['column'].unique() ※データ値のユニークな種類を確認できる。 |
知っていると便利なコマンド
データフレームの結合(pd.merge)
2つのデータフレームに対してSQLの結合(内部、外部、LEFT、RIGHT)と同じことが簡単にできます。
具体例を以下のデータでまとめました。
X =pd.DataFrame({'ID':['A0001', 'A0002', 'A0003'], '社員名':['斎藤太郎', '小林レイ', '桑原啓介']})
Y =pd.DataFrame({'ID':['A0002', 'A0003', 'A0004'], '年齢':['23', '33', '43']})
こんな2つのデータです。
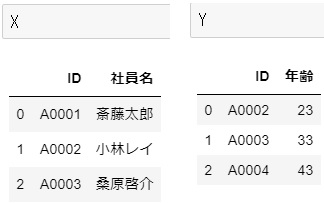
pd.merge(X, Y, on='ID', how='inner') #内部結合 pd.merge(X, Y, on='ID', how='left') #left結合 pd.merge(X, Y, on='ID', how='right') #right結合 pd.merge(X, Y, on='ID', how='outer') #外部結合
結果は以下の通り(左上:inner、左下:right、右上:left、右下:outer)