
こんにちは。sinyです。
この記事では、Flickerという画像検索WEBサイトからPythonを使って画像データを自動収集する方法をご紹介します。
Flickerとは?
Flickerとは個人の写真や画像を共有できるサイトです。

日本語で検索してもちゃんと検索結果が表示されるので機械学習、ディープラーニングの画像素材としても利用できると思います。
今回は、Frickrサイトに対応したAPI「flickrapi」を使って指定したキーワードの画像を自動収集するプログラム例を紹介します。
まずはAPIキーとSecretキーを取得しよう
flickrapiを利用するには、以下のステップが必要です。
- Yahoo.comのIDを取得(yahoo.co.jpのユーザは不可で.comのユーザが必要)
- APIキーとSecretキーの取得
以下の手順に従ってAPIキーを発行しましょう。
Flickrにアクセスして、画面右上の「Sign up」ボタンを押します。
以下のようにyahoo.comのユーザ登録画面が表示されるのでユーザ登録をしましょう。
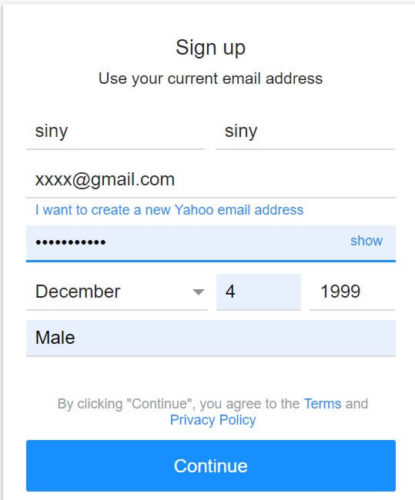
ユーザ登録が完了したら改めてFlickrにアクセスして、画面したの「Developers」をクリック。
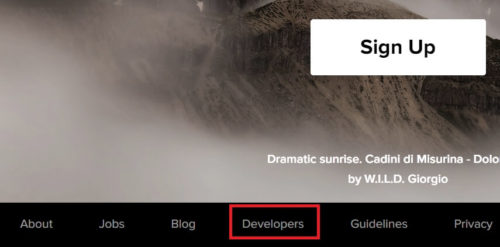
下記画面の「API」をクリック。

下記画面の「Request an API key」をクリック。
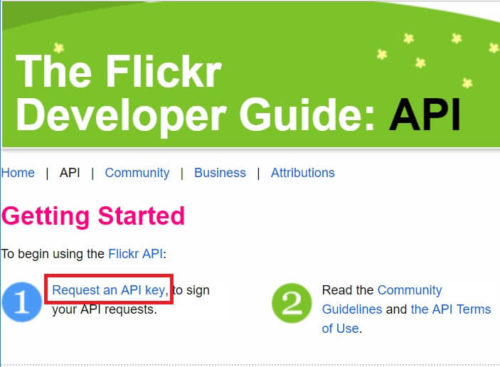
下記画面の「Request an API Key」をクリック。
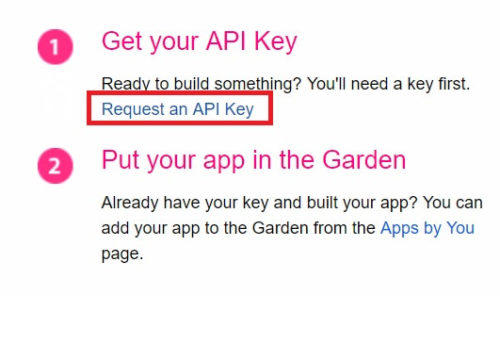
Flickrへのログオン画面が表示されるので、Emailアドレスを入力してログオンしましょう。
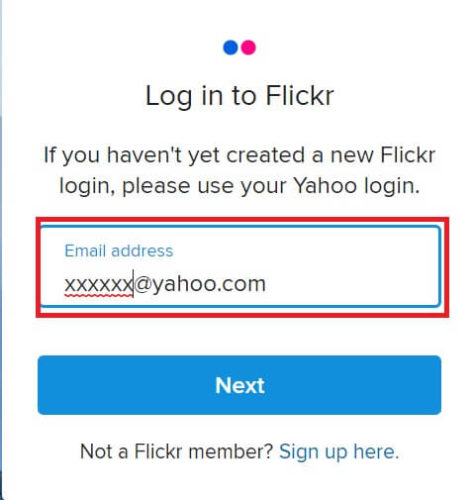
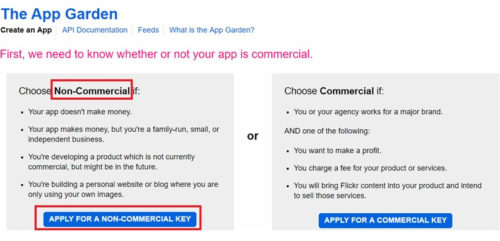
「Non-Commercial」の「APPLY FOR A NON-COMMERCIAL KEY」をクリック。
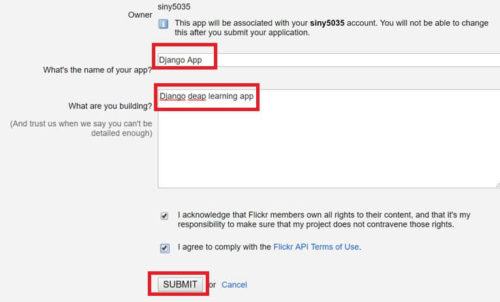
アプリの名前(任意)と、アプリの説明を適当に入力して「SUBMIT」を押しましょう。
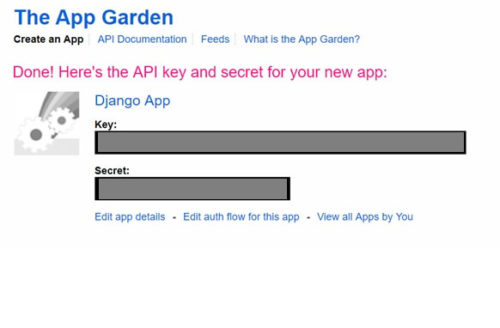
KEYとSecretが発行されるので、テキストなどにコピペしておきましょう。
FlickerAPIでデータ取得
APIキーの取得ができたら、いよいよAPIを使って画像データを自動取得してみます。
今回は、インタラクティブに動作確認するためJupterNotebook上でプログラムを実行してみます。
まずは、必要なモジュールをインストールします。
pip install flickrapi pip install jupyter
jupyter notebookコマンドでNotebookを起動して新しいノートを作ったら以下のコードを記載していきましょう。
from flickrapi import FlickrAPI from urllib.request import urlretrieve #画像をダウンロードする際に利用 import os, time, sys key ="<APIキーを指定>" secret = "<Secretキーを措定>" wait_time = 1 #検索のWait時間を指定(1秒間隔で取得) keyword = "ねこ" #検索したいキーワードを指定 savedir = "./" + keyword #画像を保存するディレクトリを指定 flickr = FlickrAPI(key, secret, format='parsed-json') #FlickrAPIクラスからインスタンスを生成 keyword = "ねこ" #検索したいキーワードを指定
FlickrAPIクラスにAPIキー、Secret情報とフォーマットを指定してflickrインスタンスを作成します。
検索キーワードは「ねこ」とします。
続いて、flickr.photos.searchメソッドを使ってAPI経由で「ねこ」画像の情報を取得します。
result = flickr.photos.search(
text = keyword, #検索キーワードを指定
per_page = 100, #取得枚数を指定
media = 'photos', #データの種類を指定
sort = 'relevance', #最新から取得
safe_search = 1, #暴力的な画像は対象外にする
extras = 'url_q, license' #URLとライセンス情報を取得する。
)
flickr.photos.searchメソッドの詳細パラメータについて知りたい方は以下を参照してみてください。
今回は、「ねこ」の画像情報を100枚取得してみます。
上記コードを実行すると、result変数には長さ2のdict型のデータ(result['photos']とresult['stat']の2つ)が格納されます。
写真に関するデータはキーが「photos」の方に複数個格納されています。(下記参照)
{'photos': {'page': 1, 'pages': 585644, 'perpage': 2, 'total': '1171287', 'photo': [{'id': '5306800458', 'owner': '54021464@N03', 'secret': '3c6d555650', 'server': '5130', 'farm': 6, 'title': 'Motorbike', 'ispublic': 1, 'isfriend': 0, 'isfamily': 0, 'license': '4', 'url_q': 'https://live.staticflickr.com/5130/5306800458_3c6d555650_q.jpg', 'height_q': '150', 'width_q': '150'}, {'id': '3434982322', 'owner': '58616528@N00', 'secret': '37a55ac118', 'server': '3584', 'farm': 4, 'title': 'Motorbike', 'ispublic': 1, 'isfriend': 0, 'isfamily': 0, 'license': '0', 'url_q': 'https://live.staticflickr.com/3584/3434982322_37a55ac118_q.jpg', 'height_q': '150', 'width_q': '150'}]}, 'stat': 'ok'}
では実際にAPI経由でねこの写真データをダウンロードしてみます。
photos = result['photos'] #写真データ部分を取り出す。
download_path = os.path.join(current_dir, keyword) #検索ワードのフォルダパス
for i, photo in enumerate(photos['photo']):
url = photo['url_q']
filepath = savedir + '/' + photo['id'] + '.jpg'
if not os.path.exists(download_path): #検索ワードのフォルダがなければ生成
current_dir = os.path.dirname(os.path.abspath("__file__"))
os.mkdir(os.path.join(current_dir, keyword))
urlretrieve(url, filepath) #写真データをダウンロード
time.sleep(wait_time) #1秒待機
photos['photo']に写真情報が格納されているので、enumerateでループ処理を回して画像のURL情報photo['url_q']を取得した後、urlretrieveメソッドを使って指定したURLの画像をローカルPC上にダウンロードします。
こんな感じでファイルがダウンロード出来ればOKです。
以上、Flickerを利用した画像データの自動収集方法でした。
とっても簡単に大量画像を自動収集できるので、ぜひ試してみてください。














