こんにちは。sinyです。
昨今、ディープラーニングが流行っていますが、今回はAverage Hashという基礎的な理論を使った類似画像検索プログラムをPythonで書いて検証してみました。
プログラム自体は至って簡単ですので、興味のある方はぜひ試してみてください。
Average Hashとは?
Average Hashは画像の形状を手軽に計算することができる手法の1つです。
画像から類似度を計算して比較することで、画像が似ているかどうかを判定するというものです。
Average Hashの計算は以下の手順になっています。
- 画像サイズを圧縮
- グレースケールに変換
- 画素の平均値を計算
- 各画素の値が平均値より上なら1、下なら0に変換
Average Hashで類似画像検出の実装
Average Hashで類似画像検索がどの程度できるのか検証してみました。
事例としては、メルカリの洋服系画像を5000枚ほどスクレイピングで収集し、その画像を素材にしました。
具体的には、「レディースのトップス」というカテゴリの洋服画像(下図)を使いました。
プログラムの解説
まず、必要なライブラリを読み込みます。
from PIL import Image
import numpy as np
import glob
import os
import matplotlib.pyplot as plt続いて初期値を設定します。
size = 64 #圧縮サイズの指定
target_file = r"C:\Users\user\scrp\data\sample.jpg" #類似検索対象の画像
search_dir = r"C:\Users\user\scrp\data\img" #検索対象の画像(約5000枚)が格納されているフォルダを指定
次に、メインとなるAverage Hashの関数と、Average Hashの計算結果の値の差異を比較するためにハミング距離というものを計算します。
ハミング距離は、2つのAverage Hash(ベクトル値)の差分情報だけを合計した値として計算します。
# 画像データをAverage hashに変換
def average_hash(target_file, size):
img = Image.open(target_file) # Image.Openで画像ファイルをオープン
img = img.convert('L').resize((size, size), Image.ANTIALIAS) # グレースケール変換&アンチエイリアス処理で圧縮
px = np.array(img.getdata()).reshape((size, size)) # 画素データを取得してリサイズ
avg = px.mean() # 画素値の平均値を取得
px = 1 * (px > avg) # 画素データ(px)で平均より大きい要素を1に、それ以外は0に変換
return px
# 2つのAverageHash値間のハミング距離を求める
def hamming_dist(a, b):
a = a.reshape(1, -1) # 1次元に変換
b = b.reshape(1, -1) # 1次元に変換
dist = (a != b).sum() # 要素が異なる部分の合計値を計算
return dist
では、まず、検索したい画像のAverage Hash値を求めてみます。
target_dist = average_hash(target_file, size)実行結果としてAverage Hash値(target_dist)として形状(64,64)のデータが生成されます。
続いて、検索対象となる約5000ファイルの情報を読み込みます。
images = glob.glob(os.path.join(search_dir, "*.jpg"))
今回は4647個の画像ファイルを用意しました。
では、この4647個のファイルをすべて読み込みAverage Hash値を計算し、検索したい画像のAverage Hash値(target_dist)に対するハミング距離を一気に求めます。
※rateの値はハミング距離に対して類似画像と判定する閾値です。
rate =2.0
result = []
for i, fname in enumerate(images):
dist = average_hash(fname, size)
diff = hamming_dist(target_dist, dist) / 256
if diff < rate:
result.append([diff,fname])
上記プログラムを実行すると、ハミング距離がrate以下である画像の情報がresult変数に格納されます。
※resultの第1要素がハミング距離、第2要素が対象画像のファイルパス
Out[605]:
[[1.6875, 'C:\\Users\\sinfo\\scrp\\data\\img\\13_32.jpg'],
[1.875, 'C:\\Users\\sinfo\\scrp\\data\\img\\14_78.jpg'],
[1.875, 'C:\\Users\\sinfo\\scrp\\data\\img\\15_4.jpg'],
[1.8203125, 'C:\\Users\\sinfo\\scrp\\data\\img\\16_62.jpg'],
[1.79296875, 'C:\\Users\\sinfo\\scrp\\data\\img\\18_60.jpg'],
[0.0, 'C:\\Users\\sinfo\\scrp\\data\\img\\1_29.jpg'],
[1.54296875, 'C:\\Users\\sinfo\\scrp\\data\\img\\1_8.jpg'],
[1.953125, 'C:\\Users\\sinfo\\scrp\\data\\img\\20_10.jpg'],
[1.88671875, 'C:\\Users\\sinfo\\scrp\\data\\img\\21_65.jpg'],
[1.83203125, 'C:\\Users\\sinfo\\scrp\\data\\img\\21_66.jpg'],
[1.91015625, 'C:\\Users\\sinfo\\scrp\\data\\img\\22_67.jpg'],
[1.8359375, 'C:\\Users\\sinfo\\scrp\\data\\img\\27_52.jpg'],
[1.6953125, 'C:\\Users\\sinfo\\scrp\\data\\img\\28_69.jpg'],
[1.6953125, 'C:\\Users\\sinfo\\scrp\\data\\img\\29_0.jpg'],
[1.96875, 'C:\\Users\\sinfo\\scrp\\data\\img\\2_20.jpg'],
[1.6796875, 'C:\\Users\\sinfo\\scrp\\data\\img\\32_51.jpg'],
[1.8046875, 'C:\\Users\\sinfo\\scrp\\data\\img\\35_39.jpg'],
[1.90234375, 'C:\\Users\\sinfo\\scrp\\data\\img\\35_43.jpg'],
[1.765625, 'C:\\Users\\sinfo\\scrp\\data\\img\\37_45.jpg'],
[1.234375, 'C:\\Users\\sinfo\\scrp\\data\\img\\42_20.jpg'],
[1.90625, 'C:\\Users\\sinfo\\scrp\\data\\img\\45_39.jpg'],
[1.8046875, 'C:\\Users\\sinfo\\scrp\\data\\img\\49_0.jpg'],
[1.86328125, 'C:\\Users\\sinfo\\scrp\\data\\img\\49_3.jpg'],
[1.30078125, 'C:\\Users\\sinfo\\scrp\\data\\img\\4_40.jpg'],
[1.9296875, 'C:\\Users\\sinfo\\scrp\\data\\img\\52_57.jpg'],
[1.2421875, 'C:\\Users\\sinfo\\scrp\\data\\img\\54_21.jpg'],
[1.484375, 'C:\\Users\\sinfo\\scrp\\data\\img\\56_9.jpg'],
[1.89453125, 'C:\\Users\\sinfo\\scrp\\data\\img\\57_11.jpg'],
[1.51953125, 'C:\\Users\\sinfo\\scrp\\data\\img\\7_11.jpg']]
これをmatplotlibで描画してみます。
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
img = Image.open(target_file)
plt.imshow(img)
plt.tick_params(labelbottom="off",bottom="off") # x軸の削除
plt.tick_params(labelleft="off",left="off") # y軸の削除
plt.figure(figsize=(128,128))
plt.subplots_adjust(wspace=0.5,hspace=0.5)
for i, item in enumerate(result):
plt.subplot(8, 8, i+1)
img = cv2.imread(item[1], cv2.COLOR_BGR2RGB)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #BGR -> RGB順に
plt.tick_params(labelbottom="off",bottom="off") # x軸の削除
plt.tick_params(labelleft="off",left="off") # y軸の削除
plt.imshow(img)
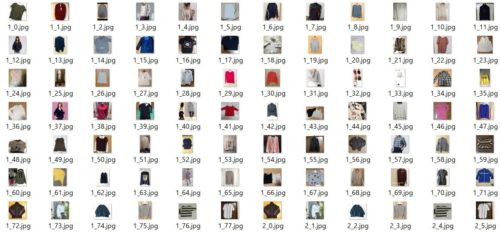
結果は以下のようになりました。
一番上の大きい画像が検索ターゲットの画像で、下の小さい画像が類似として判定された画像です。
どうも、単純なAverage Hash値の計算ではうまく類似画像を判定できないようです。
※圧縮サイズをもっと増やしてみましたが改善は見られませんでした。


# 画像データをAverage hashに変換
def average_hash(target_file, size):
img = Image.open(target_file)
img = img.resize((size, size), Image.ANTIALIAS) # 変換モードをRGBへ。
px = np.array(img.getdata()).reshape((size, size, 3)) #リサイズの形状を3次元に変換
avg = px.mean()
px = 1 * (px > avg)
return px変更したのは以下の2か所。
※読み込んだ画像をグレースケール化しないように変更。
img = img.resize((size, size), Image.ANTIALIAS) # 変換モードをRGBへ。※画素データをArray化してReshapeする際にカラー画像を扱うために形状(size,size,3)に変換。
px = np.array(img.getdata()).reshape((size, size, 3)) #リサイズの形状を3次元に変換上記設定で、再度類似度を計算して、グラフ描画してみたところ以下のような結果になりました。
※赤枠は完全同一画像

全く違う洋服もありますが、全体的にはピンク系統の似たような形状の画像が抽出されました。
5000枚近くの画像からこれだけ絞り込めればそれなり使えそうな気はします。
まとめ
- Average Hash値そのままの計算フロー(グレースケール化)だとうまく検出できない。
- グレースケール化しないようにすればそれなりの精度はでる。
- ただし、画像特性によるところが大きく、Mnistの手書き数字のような画像だとうまく画像判定できなかった。
- おそらく検索対象の画素数がもともと小さいと精度はあがらない。(画素数が大きい画像だと精度がでるかも?)
- ディープラーニングを使わなくても画像特性と用途によってはお手軽に実装できる類似画像判定機として利用できる可能性あり
以上、Average Hash値を使った類似画像判定に関する記事でした。