【Django × Deep Learning】Seq2Seq + Attention で機械翻訳モデルを構築する【前編】

目次
Django × Deep Learning · 翻訳デモアプリ【前編】
翻訳エンジンを自分で作ってみたい方向けに、本記事では Seq2Seq + Attention 機構を使った ニューラル機械翻訳モデルの基礎理論と Keras 実装 を、前編・後編の 2 記事構成で解説します。前編にあたる本記事では、対訳コーパスの準備、データの前処理、Encoder-Decoder モデルの構築、学習・評価までをカバー。Web アプリ化(Django 組込)は 後編記事 を参照してください。
この記事では、ディープラーニングのSeq2seqを使った簡単な英語→日本語翻訳アプリをDjangoで実装する方法をご紹介します。
最終的に以下のような英和翻訳のデモアプリをDjangoで作成します。
Seq2seqによるモデル学習からDjango実装までのボリュームが多いため、前編と後編に記事を分割しています。(本記事は前編です)
Seq2Seqの基礎については以下の記事を参考にしてください。

user@sinyblog:~/article ❯ 01_section_1.md実装内容
seq2seqのコードは、以下のGitサイトに掲載されているKerasのサンプルコードを使っていきます。
また、学習に使う英語と日本語データはこちらの「Japanese - English jpn-eng.zip」を利用しました。
jpn-eng.zipを解凍するとjpn.txtというファイルがありますので、これを学習データとして利用します。
jpn.txtの中身は以下のように「英文と日本語訳」が記載されたテキストデータになっていて、1万語の文章が記載されています。
Go. 行け。
Go. 行きなさい。
Hi. やっほー。
Hi. こんにちは!
Run. 走れ。
user@sinyblog:~/article ❯ 02_keras_seq2seq.mdKerasのSeq2seqで英語翻訳モデルを構築
まず最初に、必要なモジュール、初期パラメータを設定します。
from __future__ import print_function
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
from keras import backend as K
batch_size = 64 # バッチサイズ
epochs = 100 # エポックサイズ.
latent_dim = 256 # エンコーディングの次元数
num_samples = 10000 # サンプル数
# データファイルのパス
data_path = 'jpn.txt'
K.clear_session()
- 学習データは10000語あるので、num_samplesを10000に設定します。
- data_pathには学習用のファイル「jpn.txt」を指定します。
- その他は、keras,numpyといった必要なモジュールをインポートします。
英語、日本語データをベクトル化
まずは、jpn.txtを読み込んで以下の情報に分けます。
- input_texts(英語文)
- target_texts(日本語文)
- input_characters(英語の単語の種類)
- target_characters(日本語の単語の種類)
input_texts = [] #英語のデータ
target_texts = [] #日本語のデータを格納
input_characters = set() #英文に使われている文字の種類
target_characters = set() #日本語に使われている文字の種類
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text = line.split('\t')
# ターゲット分の開始をタブ「\t」で、終了を改行「\n」で表す。
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)※target_text(正解となる日本語文)は開始をタブ「\t」で、終了を改行「\n」で表します。
input_textsには英語、target_textsには日本語が格納されるので、試しに10個だけ値を確認してみましょう。
#最初の10個を確認
for i in range(10):
print(input_texts[i],":", target_texts[i])
Go. : 行け。
Go. : 行きなさい。
Hi. : やっほー。
Hi. : こんにちは!
Run. : 走れ。
Run. : 走って!
Who? : 誰?
Wow! : すごい!
Wow! : ワォ!
Wow! : わぉ!入門
jpn.txtに格納されている英語、日本語のトークン数、最大長の値を取得します。
#ソート
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
#インプット(英語)の単語数
num_encoder_tokens = len(input_characters)
#アウトプット(日本語)の単語数
num_decoder_tokens = len(target_characters)
#一番長い英文の数
max_encoder_seq_length = max([len(txt) for txt in input_texts])
#一番長い日本語分の数
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('input_texts:', len(input_texts))
print('num_encoder_tokens(英語):', num_encoder_tokens)
print('num_decoder_tokens(日本語):', num_decoder_tokens)
print('max_encoder_seq_length(英語):', max_encoder_seq_length)
print('max_decoder_seq_length(日本語):', max_decoder_seq_length)
結果は以下のようになります。
input_texts: 10000
num_encoder_tokens(英語): 72
num_decoder_tokens(日本語): 1476
max_encoder_seq_length(英語): 22
max_decoder_seq_length(日本語): 32
続いて、英語、日本語トークンの辞書作成とベクトル化(One-Hot表現)を行います。
辞書は以下のような形で日本語と英語それぞれについて作成します。
- input_token_index = {'A': 20, 'B': 21, 'C': 22, 'D': 23, 'E': 24, 'F': 25, 'G': 26, 'H': 27,・・・・}
- target_token_index ={'ぁ': 44, 'あ': 45, 'い': 46, 'う': 47, 'え': 48, 'ぉ': 49, 'お': 50,・・・}
#英語辞書データの生成
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
#日本語辞書データの生成
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
#ベクトルの入れ物を定義
#形状は (入力データ数,文章の最大長,トークン数)の3次元
# (10000, 22, 72) 英語
# (10000, 32, 1476) 日本語
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
# インプットデータ(英語)、アウトプットデータ日本語)から1つずつ抽出して
# 辞書を使ってインデックスに変換して、one-Hot表現に変換
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_dataは1タイムステップ進んでいるので正解データとしては1ステップ前の位置にセット。
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
print("英語の形状",encoder_input_data.shape)
print("日本語の形状",decoder_input_data.shape)
- decoder_target_dataは1タイムステップ進んでいるので、時刻tにおける正解データとするために1ステップ前(t-1)の位置にセットします。(以下の部分)
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
英語、日本語のone-hot表現後の形状は以下のようになります。
・英語の形状 (10000, 22, 72)
・日本語の形状 (10000, 32, 1476)
Seq2seqモデルの定義
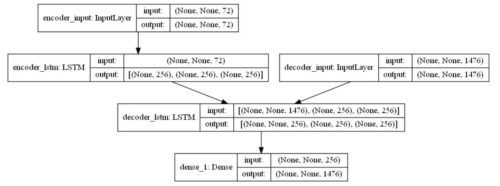
seq2seqモデルを以下のように定義します。
- encoderに入力データ(英語)を与え、内部状態(2つ)を出力する。
- decoderには、(日本語)データを与え、初期状態にencoderが出力した内部状態をセットする。
- 完全な出力シーケンスを返すようにデコーダを設定する。
- decoderも内部状態を返すが、学習では使わないが、推論時に利用する。
# encoderモデルの定義
# 入力長さは可変のためNone,トークン数=num_encoder_tokensを指定
encoder_inputs = Input(shape=(None, num_encoder_tokens),name="encoder_input")
encoder = LSTM(latent_dim, return_state=True,name="encoder_lstm")
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# encoderのアウトプットは不要なため内部状態2つのみを保持
encoder_states = [state_h, state_c]
#decoderの定義
decoder_inputs = Input(shape=(None, num_decoder_tokens),name="decoder_input")
# 初期状態としてencoderから出力された内部状態 encoder_statesセットする。
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True,name="decoder_lstm")
# 出力のみを取得
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
#全結合層を定義しSoftmaxで単語の確率を出力するモデルを定義
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# encoder_input_dataとdecoder_input_dataを decoder_target_dataに変換するモデルを定義
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
学習モデルは以下のようになります。
学習の実行
続いて以下のコードで学習を行います。
# 学習
from keras.callbacks import EarlyStopping
# val_lossに改善が見られなくなってから、5エポックで学習は終了
early_stopping = EarlyStopping(monitor="val_loss", patience=3)
# 多クラス分類なのでcategorical_crossentropyを指定
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
history = model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
callbacks=[early_stopping])
#モデルの保存
model.save('s2s.h5')
学習はインプットにencoder_input_data(英語)と decoder_input_data(日本語)を、アウトプットに予測値となる日本語をセットします。
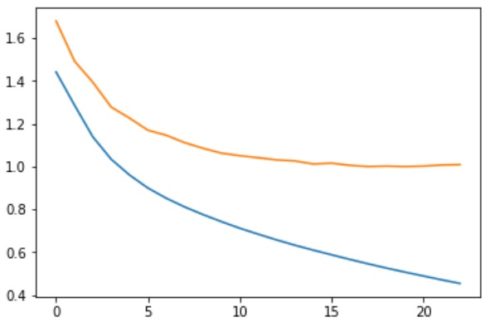
Eealyストップを設定して検証のLOSSが5連続で改善されない場合学習を終了するようにしています。
ちなみに23エポックくらいで完了しました。
念のため誤差の推移を確認すると以下のようになりました。
%matplotlib inline
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(np.arange(len(loss)), loss)
plt.plot(np.arange(len(val_loss)), val_loss)
plt.show()
予測用モデルの構築
予測モデルは以下のようにエンコーダーモデルとデコーダーモデルを構築します。
- encoder:入力を受け取って状態を返す。
- decoder:入力と状態を受け取って出力と状態を返す。
# encoderモデルの定義
from keras.models import load_model
model = load_model('s2s.h5', compile=False)
#encoder_inputsを入力、出力はencoderの内部状態であるencoder_statesを指定
#encoder_inputs~ encoder_states間にあるLSTM層は学習済みのものが利用される。
encoder_model = Model(encoder_inputs, encoder_states)
# decoderの定義
# #形状は中間層と同じlatent_dim=(256,)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
#内部状態をリスト形式にして1つの変数にする。
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# 既存の学習済みLSTM層(decoder_lstm)を使用し、初期状態にdecoder_states_inputsを指定
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
# decoderの内部状態2つをリストで結合
decoder_states = [state_h, state_c]
# 既存の学習済み全結合層(decoder_dense)を使用
decoder_outputs = decoder_dense(decoder_outputs)
# リストで結合
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# モデルの保存
encoder_model.save('encoder_model.h5')
decoder_model.save('decoder_model.h5')
逆引きトークンインデックスを作成
続いて、予測の際にトークンのIndexから単語を取得するため逆引きトークンインデックスを作成します。
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())input_token_index(英語)とtarget_token_index(日本語)それぞれに対してキーと値を入れ替えた辞書を生成します。
以下のようなイメージですね。
■【変換前】
input_token_index: ('A', 20), ('B', 21), ('C', 22), ('D', 23), ('E', 24), ('F', 25),
target_token_index: ('ぁ', 44), ('あ', 45), ('い', 46), ('う', 47), ('え', 48), ('ぉ', 49)
■【変換後】
reverse_input_char_index: (20, 'A'), (21, 'B'), (22, 'C'), (23, 'D'), (24, 'E'), (25, 'F'),
reverse_target_char_index: (44, 'ぁ'), (45, 'あ'), (46, 'い'), (47, 'う'), (48, 'え'), (49, 'ぉ')
予測値作成用関数の作成
続いて、入力に英文の状態ベクトルを与えて、出力(日本語訳)を出すdecode_sequence関数を定義します。
def decode_sequence(input_seq):
# 入力文(input_seq)を与えてencoderから内部状態を取得
states_value = encoder_model.predict(input_seq)
# 長さ1の空のターゲットシーケンスを生成
target_seq = np.zeros((1, 1, num_decoder_tokens))
# ターゲットシーケンスの最初の文字に開始文字であるタブ「\t」を入力
target_seq[0, 0, target_token_index['\t']] = 1.
# シーケンスのバッチのサンプリングループ
# バッチサイズ1を想定
stop_condition = False
# 初期値として返答の文字列を空で作成。
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# トークンをサンプリングする
# argmaxで最大確率のトークンインデックス番号を取得
sampled_token_index = np.argmax(output_tokens[0, -1, :])
# Index空文字を取得
sampled_char = reverse_target_char_index[sampled_token_index]
# 返答文字列にサンプリングされた文字を追加
decoded_sentence += sampled_char
# 終了条件:最大長に達するか停止文字を見つける。
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# ターゲット配列(長さ1)を更新
# 長さ1の空のターゲットシーケンスを生成
target_seq = np.zeros((1, 1, num_decoder_tokens))
#予測されたトークンの値を1にセットし次の時刻の入力にtarget_seqを使う。
target_seq[0, 0, sampled_token_index] = 1.
# 内部状態を更新して次の時刻の入力に使う。
states_value = [h, c]
return decoded_sentence
動作を確認してみます。
訓練データ(英文)からランダムに3つの文を選択して翻訳し、上記decode_sequence関数に与えることで日本語の返答結果を確認します。
import numpy as np
for _ in range(10):
seq_index = np.random.randint(len(input_texts))
#encoderへの入力encoder_input_data(英語)から文章を1つ取得
input_seq = encoder_input_data[seq_index: seq_index + 1]
#入力文(英語)を日本語に翻訳
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
実行結果例です。
精度はあまり高くありませんが、文章によっては割と正確に翻訳できているものもあります。
-
Input sentence: Aren't you frightened?
Decoded sentence: 君はあなたのことが大嫌いなんだ。
-
Input sentence: He's asleep.
Decoded sentence: 彼は幸せだ。
-
Input sentence: I think so.
Decoded sentence: そう思います。
インタラクティブに翻訳を実行
続いて、インタラクティブに英文を入力して、翻訳された結果を表示できるようにしてみます。
#使用できない文字(コーパスにない文字)があったときに無効な文字を判定するために使う。
def is_invalid(message):
is_invalid =False
for char in message:
if char not in input_characters:
is_invalid = True
return is_invalid
# 文章をone-hot表現に変換する関数
def sentence_to_vector(sentence):
vector = np.zeros((1, max_encoder_seq_length, num_encoder_tokens))
for j, char in enumerate(sentence):
vector[0][j][input_token_index[char]] = 1
return vector
is_invalid関数は、辞書に登録されていない単語が入力された場合に「英文を入力してください」という表示をさせるために使います。
sentence_to_vector関数は、入力された英文をOn-Hot表現に変換する関数です。
print("英文を入力してください。:")
message = ""
while message != "exit":
while True:
message = input()
if not is_invalid(message):
break
else:
print("英文を入力してください。")
vec = sentence_to_vector(message)
response = decode_sequence(vec)
print(response)
上記コードを実行すると、入力受付待ちになるので、英文を入力してEnterキーを押すと、翻訳された結果が下に表示されます。
英文を入力してください。:
What's your name?
お名前は何ですか。
以上、ディープラーニング+Djangoで言語翻訳デモアプリの作成【前編】でした。
後編では、この記事で学習させた翻訳モデルをDjangoに実装していきます。