Claude Code のトークン代を、仕組みから理解して削る|キャッシュ・出力単価・モデル切替の全知識
目次
- 1 Claude Code のトークン代を、仕組みから理解して削る
- 1.1 user@sinyblog:~/article ❯ 01_cost_structure.mdまず押さえる「コスト構造」3つ
- 1.2 user@sinyblog:~/article ❯ 02_prompt_cache.mdプロンプトキャッシュ:最大の節約装置
- 1.3 user@sinyblog:~/article ❯ 03_models_subagents.mdモデル切替とサブエージェント
- 1.4 user@sinyblog:~/article ❯ 04_caveman_mode.md原始人モード:出力を削る
- 1.5 user@sinyblog:~/article ❯ 05_keep_context_small.mdコンテキストを小さく保つ
- 1.6 user@sinyblog:~/article ❯ 06_switch_effects.mdモデルを切り替えると会話とキャッシュはどうなる?
- 1.7 user@sinyblog:~/article ❯ 07_cheatsheet.md早見表:効果の大きい順
- 1.8 user@sinyblog:~/article ❯ 99_summary.mdまとめ
Anthropic Official Docs · 2026 Edition
Claude Code のトークン代を、仕組みから理解して削る
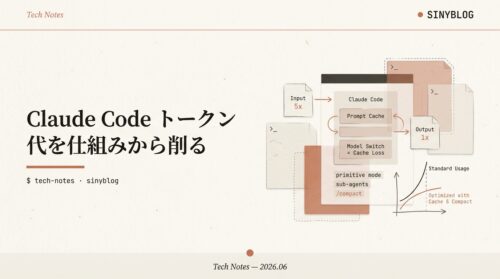
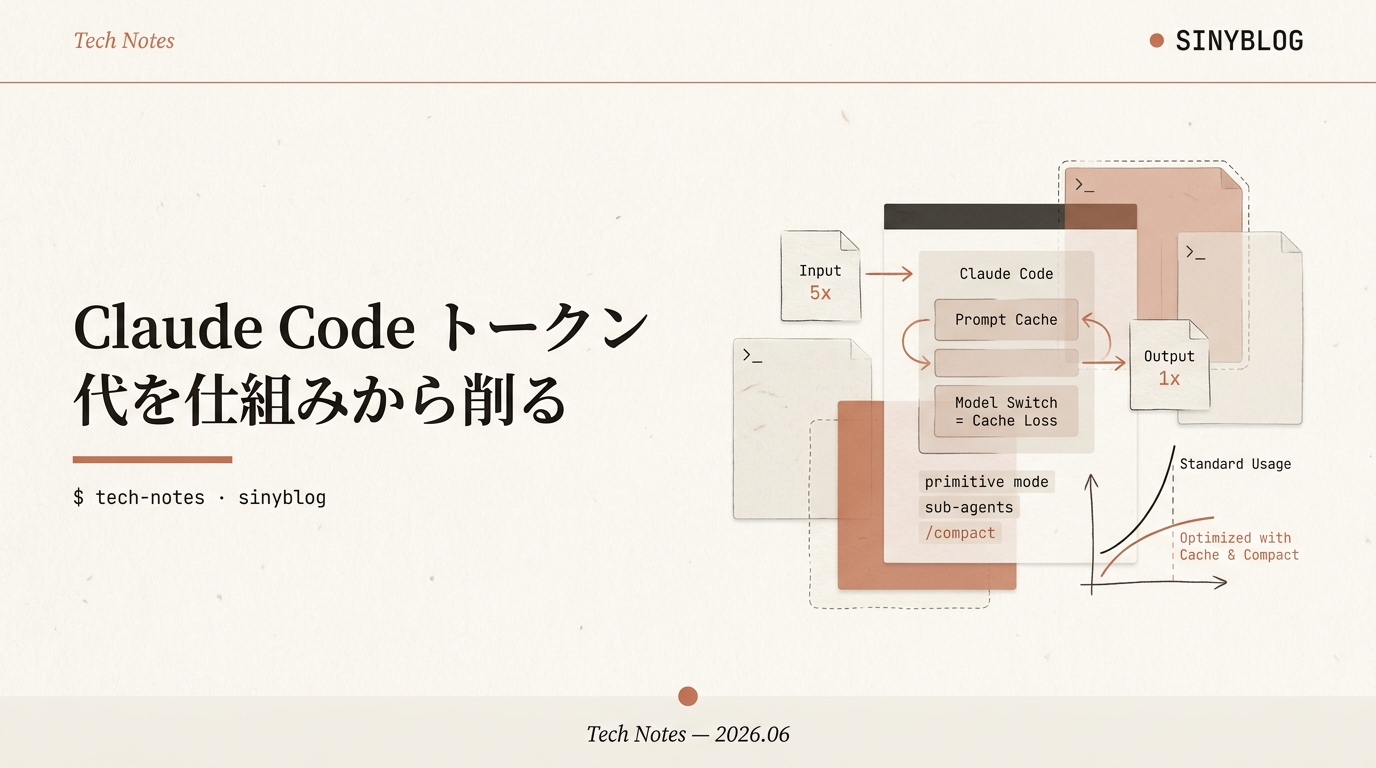
「トークン代が高い」「Max $200 でもレートリミットに当たる」——その多くは使い方で変わります。料金が決まる仕組み(キャッシュ・出力単価・モデル切替)を押さえれば、同じ作業でも消費トークンはかなり減らせます。公式ドキュメント起点で、仕組みと節約テクを整理しました。
仕組みを一言でいうと、コストは「先頭は使い回し、末尾だけ満額」というプロンプトキャッシュの構図でほぼ決まります。この1点を理解するだけで、CLAUDE.md を軽く保つ・モデル切替を節目でまとめる・無駄に喋らせない、といった習慣がなぜ効くのかが腑に落ちます。本記事は公式ドキュメント[1]をベースに、実機検証も交えて整理したものです。
-
0倍
出力は入力より高い -
0分の1
キャッシュ読取の単価 -
0つ
キャッシュを全損させる操作
user@sinyblog:~/article ❯ 01_cost_structure.mdまず押さえる「コスト構造」3つ
公式の料金(2026年6月時点、$ / 100万トークン)はこうなっています。出力は入力より高く、その比率は全モデル共通でおよそ5倍です。
| モデル | 入力 | 出力 | キャッシュ読取 | 出力/入力比 |
|---|---|---|---|---|
| 🟣 Opus 4.8 | $5 | $25 | $0.5 | 5倍 |
| 🔵 Sonnet 4.6 | $3 | $15 | $0.3 | 5倍 |
| 🟢 Haiku 4.5 | $1 | $5 | $0.1 | 5倍 |
ここから、効いてくる原則は3つです。
- 出力トークンは入力の5倍高い(全モデル共通)。だから「Claude に長々と喋らせない」のが一番効きます。後述の原始人モードの核心もここです。
- キャッシュ読取は通常入力の約1/10。同じプレフィックスを使い回せれば、実質9割引です。Claude Code はこれを自動で使います。
- サブスク(Max/Pro)か API かで「コスト」の意味が違う。サブスクはドル課金ではなく枠の消費なので、各テクは「枠を長持ちさせる」方向で効きます。
“Claude Code charges by API token consumption.” / “the average cost is around $13 per developer per active day and $150-250 per developer per month” [1]
user@sinyblog:~/article ❯ 02_prompt_cache.mdプロンプトキャッシュ:最大の節約装置
Claude Code は、何もしなくてもプロンプトキャッシュを使っています。これを「壊さない」ことが、地味ですが一番効く節約です。仕組みはシンプルで、会話は毎ターン丸ごと送り直されますが、前回と同じ"先頭部分"は約1/10で再利用できる、というものです。キャッシュはプレフィックス一致で判定されるので、途中で1バイトでも変わると、そこから後ろは全部やり直しになります。
“The match is exact, so a change anywhere in the prefix recomputes everything after it. There is no per-file or per-segment caching.” [2]
リクエストは先頭から「3つの層」が積まれています。先頭ほど変わりにくく、変わったときの破壊力(再計算の範囲)が大きいです。
| 層(先頭→末尾) | 中身 | 変化するタイミング |
|---|---|---|
| ① システムプロンプト | Claude Code の役割指示・ツール定義・出力スタイル・環境スナップショット | モデル / effort / MCP 増減 / 本体バージョンUP |
| ② プロジェクト文脈 | プロジェクト直下と個人グローバルの CLAUDE.md | セッション開始 / clear / compact |
| ③ 会話 | 指示・返答・ツール実行結果(読んだファイル・コマンド出力) | 毎ターン末尾に追記(普段の変化はここ) |
①が変わると②③も巻き添えで全部やり直し(最も高い)になります。①の「役割・振る舞いの指示」は Anthropic が Claude Code 本体に組み込み済みで、こちらは編集しません。自分でルールを足したいときは、組み込み本体ではなく CLAUDE.md(②の層)を使うのが基本です。
セッション途中で CLAUDE.md を編集しても、その場では反映されません(次の開始・/clear・/compact まで持ち越し)。“Editing them mid-session does not invalidate the cache, but the edit also doesn't apply.” [2]
図解:ターンが進むほど"続き"は安い
毎ターン「これまで全部+今回の新規」を読み直しますが、変わっていない先頭は再利用(約1/10)、増えた末尾だけ満額になります。下のシミュレーションは、ターンが1コマずつ進むと緑(再利用)の先頭が伸び、満額の橙は右端に1つ増えるだけ——そして4回目で先頭が変わると全部が赤に転落する、という挙動をゆっくり再生します。
| システム | CLAUDE.md | やり取り1 | やり取り2 | やり取り3 | |
|---|---|---|---|---|---|
| 1回目 | 新規 | 新規 | 新規 | ||
| 2回目 | 再利用 | 再利用 | 再利用 | 新規 | |
| 3回目 | 再利用 | 再利用 | 再利用 | 再利用 | 新規 |
| 4回目 | 全損 | 全損 | 全損 | 全損 | 全損 |
スクロールで自動再生されます。各ターンの「リクエストの中身」が1コマずつ進みます。
ターン 0 / 4
ポイントは2つです。🟧(新規・満額)は毎ターン右端に1つ増えるだけで、左側はぜんぶ🟩(再利用)になる。だから会話が伸びても安い。でも4回目のように先頭が変わると後ろ全部が🟥(作り直し)=全損になる。これがモデル切替・effort切替・バージョンUP・MCP増減で起きます。
キャッシュが切れる / 壊れるタイミング
まず TTL(割引の有効期限)です。認証方式で既定が違います。サブスク側は「プラン名」ではなく「課金方式」で決まる点に注意です。
| 認証 | 既定TTL | 備考 |
|---|---|---|
| 🟢 Claude サブスク | 1時間(自動) | Pro / Max / Team / Enterprise の席は基本1時間 |
| 🔵 APIキー / 各種クラウド | 5分 | ENABLE_PROMPT_CACHING_1H=1 で1h化 |
① Enterprise でも従量(pay-as-you-go)契約は従量側扱いで5分。② サブスクでもプラン上限を超えて usage credits 課金中は自動で5分に降格。長セッションに戻る最初の1ターンが一番高くなりがちです[2]。
次に、次のターンを「全損(全文の読み直し)」にしてしまう操作です。公式が明示している8つがこちらです。
| # | 操作 | # | 操作 |
|---|---|---|---|
| 1 | モデル切替(/model) |
5 | プラグイン有効化 / 無効化 |
| 2 | effort 切替(/effort) |
6 | ツールを丸ごと拒否(deny) |
| 3 | fast mode を ON | 7 | コンパクト(会話の要約) |
| 4 | MCP サーバ接続 / 切断 | 8 | Claude Code 本体のバージョンUP |
user@sinyblog:~/article ❯ 03_models_subagents.mdモデル切替とサブエージェント
簡単な作業は Haiku、難所だけ Opus、という使い分けが基本です。/model <alias> で即時切替、引数なしでピッカーが開きます。ただし切替=キャッシュ全損なので、チョコチョコ切り替えると損です。節目でまとめて、が正解です。
サブエージェントは、本体とは別のコンテキストウィンドウで動く"下請け"です。調べ物などをさせて、要約だけを本会話に返します。下請けを安いモデルに割り当てると、そのまま節約になります。定義は Markdown ファイルで、保存先はプロジェクト .claude/agents/ か、全プロジェクト共通なら ~/.claude/agents/ です。
---
name: run-on-sonnet
description: 渡されたタスクを Sonnet(claude-sonnet-4-6)で実行する汎用エージェント。難しくない作業を安いモデルに振りたいときに使う。
model: claude-sonnet-4-6 # ここがキモ。最新でよければ sonnet でも可
# tools: は書かない → メイン会話の全ツールを継承(=何でもできる汎用)
effort: medium
---
渡されたタスクをそのまま実行し、結果を簡潔に報告する。役割や手順を勝手に足さない。モデルだけ変えたいなら model: を claude-opus-4-8 や claude-haiku-4-5 に差し替えるだけ。tools: を書かないのが汎用化のコツで、書くとそのツールだけに絞られます。呼び出しは @run-on-sonnet このテストを直して のように名指しが確実です。全サブエージェントを一括で安価モデルに固定したいなら、最上位の環境変数 CLAUDE_CODE_SUBAGENT_MODEL=haiku が確実です。
実機で確認:親 Opus/子 Sonnet が同時に動く
セッション記録の tool_result に "resolvedModel":"claude-sonnet-4-6"、本体は "model":"claude-opus-4-8" のまま。自己申告ではなくハーネス側の記録です。
モデル名の書き方(エイリアス vs フルID)
エイリアス(opus / sonnet / haiku 等)は「そのプロバイダの最新版」に自動解決されますが、新モデルが出ると指す先が変わる=再現性はありません。バージョンを固定したいなら claude-opus-4-8 のようにフルIDを使います。
| エイリアス | Anthropic API 直(今) | Bedrock / Vertex / Foundry(今) |
|---|---|---|
opus |
Opus 4.8 | Opus 4.6 |
sonnet |
Sonnet 4.6 | Sonnet 4.5 |
haiku |
Haiku 4.5 | 最新 Haiku |
# チャット中に即切替
/model sonnet # 最新Sonnetへ
/model opus[1m] # Opusの100万トークン版へ(長い作業)
/model opusplan # 計画=Opus・実装=Sonnet の自動ハイブリッド
/model default # プラン標準に戻す
# 起動時に指定
claude --model haiku「全部列挙して難易度で自動選択」みたいな純正機能はありません(エイリアスは1個=1モデル)。代わりに目的別のしくみがあります:opusplan(計画=Opus/実装=Sonnet)、フォールバックチェーン(可用性フェイルオーバーであって賢さ/安さ選択ではない)、effort(思考の深さ)、サブエージェント。難易度で安い/高いを自動振り分けしたいなら、純正には無いので外部ルーター(claude-code-router 等)が定番です。
user@sinyblog:~/article ❯ 04_caveman_mode.md原始人モード:出力を削る
「原始人モード」は公式機能ではなく Reddit 発祥のコミュニティ手法(英語名 Caveman Prompt)です。やることは単純で、Claude に「原始人のように最小限だけ話せ」と指示して、挨拶・前置き・丁寧語・進捗ナレーション・冗長な解説を削り、出力トークンを減らします。先ほどの「出力は入力の5倍高い」と表裏一体です。
- 承知しました!それでは、ご依頼のログイン処理のバグを修正していきますね。
- まず原因を調査します。…(前置き・実況・お礼が延々と続く)
+ Done: auth.ts:42 に null チェックを追加してログインのバグを修正CLAUDE.md にこのまま貼って使えます。
## 出力ルール(原始人モード)
- 前置き・相槌・お世辞・自己説明を書かない。「やったこと → 結果」だけ報告する。
- 結論を最初に。背景・理由・代替案は、聞かれたときだけ書く。
- 完了報告は1行(例: `Done: ログイン処理のバグ修正`)。作業の逐一実況をしない。
- 箇条書き優先・1項目1行。同じ内容の言い換えや要約の重複をしない。
- コード・差分・コマンドは省略せず正確に出す(※コードは短くしない)。
- 例外:削除・force push・本番反映・課金が発生するなど「取り返しのつかない操作」の前だけは、
通常の丁寧モードに戻り、何が起きるかを段階的に説明し、確認を取ってから実行する。「75〜80%削減」のような数字は出力単体の極端な例です。コードブロックは圧縮対象外なので、実コーディングのセッション全体では1〜2割程度というのが冷静な見方です。常時ONがキツければ /caveman のようにスキル化して手動で呼ぶ手もあります。
user@sinyblog:~/article ❯ 05_keep_context_small.mdコンテキストを小さく保つ
会話履歴は毎ターン丸ごと送り直されるので、履歴を小さく保つこと自体が継続的な節約になります。公式の「Reduce token usage」に沿うと、こんな手があります。
| 手法 | 効果 |
|---|---|
🧽 /clear |
無関係な作業に移るとき新規開始。古い文脈は毎メッセージ無駄に課金される |
📦 /compact(指示付き可) |
履歴を要約圧縮(/compact Focus on … で残すものを指定) |
| 💸 安価モデル / サブエージェント | 単価・文脈の削減 |
🔌 MCP 整理(/mcp・/context) |
常時ロード分を削減 |
| 📄 CLAUDE.md → Skill 移行 | 起動時の固定文脈を軽量化(CLAUDE.md は200行以下が目安) |
| 🧠 effort / thinking を下げる | 思考は出力扱いなので効く |
| 🎯 プロンプトを具体的に | 無駄な探索ターン(=毎回の全文送信)を減らす |
画像・PDF・base64 入り Notebook はトークン消費が大きいので、可能ならテキストで渡す(Jupyter は .ipynb → .py にして編集)。指示を具体的にしてターン数を減らすのも効きます。例:「このコードベースをいい感じに改善して」より「auth.ts の login 関数に入力バリデーションを追加して」。
“Use /clear to start fresh when switching to unrelated work. Stale context wastes tokens on every subsequent message.” / “Aim to keep CLAUDE.md under 200 lines” / “Thinking tokens are billed as output tokens … reduce costs by lowering the effort level” [1]
user@sinyblog:~/article ❯ 06_switch_effects.mdモデルを切り替えると会話とキャッシュはどうなる?
ここがいちばん誤解されやすいところです。結論は2つ。会話履歴は消えないが、キャッシュは全損する。/model やスキルでモデルを切り替えても、会話履歴はそのまま新モデルに引き継がれます(リセットされません)。ただしプロンプトキャッシュはモデルごとに別物なので、切替直後の1ターンは内容が同じでも全履歴をキャッシュ無し(満額)で読み直します。これが本当の代償です。
“Each model has its own cache. Switching with /model means the next request reads the entire conversation history with no cache hits, even though the content is identical.” [2]
「大きい→小さいモデルに切替えると、いきなり compact が走る?」
これは半分正しく、しかも Opus→Sonnet の切替がまさにそのケースになり得ます。理由は、「100万トークン窓」が全モデル・全プランで常時オンではないことです。
| プラン | Opus の1M | Sonnet の1M |
|---|---|---|
| Max / Team / Enterprise | ✅ 自動でON | ⚠️ 自動対象外=usage credits が必要(無しなら200K) |
| Pro | ⚠️ credits が必要(無しは200K) | ⚠️ credits が必要(無しは200K) |
| API / 従量 | ✅ 常時フル1M | ✅ 常時フル1M |
つまり Max 等で Opus(1M)→Sonnet に切り替えると、実効の窓が 1M→200K に縮みます(Sonnet の1M は自動では効かないため)。会話履歴が200Kを超えていれば、新しい窓に収めるために自動コンパクトが走ります。スキルでモデルを切り替えた瞬間にコンパクトが走るのは、これで説明できます。なお自動コンパクトの正確な発火%は公式に記載がなく、コンパクトは会話層のキャッシュを壊します。
“On Max, Team, and Enterprise plans, Opus is automatically upgraded to 1M context … Sonnet with 1M context is not part of the automatic upgrade and requires usage credits on every subscription plan, including Max.” [3]
user@sinyblog:~/article ❯ 07_cheatsheet.md早見表:効果の大きい順
効果の大きい順に、ざっくり並べるとこうです。
| テクニック | 主な削減対象 | 効き |
|---|---|---|
| 安価モデル / サブエージェント振り分け | 入力単価 | 🟢🟢🟢 |
| プロンプトキャッシュを壊さない(切替は節目で) | 入力(約1/10化) | 🟢🟢🟢 |
| コンテキストを小さく保つ(/clear・/compact・MCP整理) | 入力(毎ターン) | 🟢🟢🟢 |
| 原始人モード(出力簡潔化) | 出力(5倍単価) | 🟢🟢(実質1〜2割) |
| effort / thinking を作業に応じて下げる | 出力(思考) | 🟢🟢 |
| Hooks で前処理(巨大ログを grep 済みで渡す) | 入力 | 🟢🟢 |
| 画像 / PDF 回避・指示具体化でターン削減 | 入出力 | 🟢🟢 |
横断的にいうと、小手先の最適化より、契約形態(定額枠の活用・安価APIへの切替)の見直しのほうが桁違いに効く、という指摘もあります[7]。サブスクなら、上記は「枠を長持ちさせる」方向で効いてきます。
user@sinyblog:~/article ❯ 99_summary.mdまとめ
コストは「先頭は使い回し、末尾だけ満額」というキャッシュの構図でほぼ決まります。だから効く習慣は、結局この3つに集約されます。
- 無駄に喋らせない。出力は入力の5倍高い(原始人モード・effort を下げる)。
- 同じ資料を読み直させない。キャッシュを壊さない(CLAUDE.md は軽く・モデル切替は節目で)。
- 担当交代は節目でまとめて。モデル切替=キャッシュ全損なので、1メッセージごとに往復しない。
特に「モデルを切り替えると会話は消えないがキャッシュは全損する」点と、「Opus→Sonnet は実効窓が縮んでコンパクトが走り得る」点は、知っているかどうかで体感コストがけっこう変わります。仕様は更新が速いので、重要な箇所は下記の一次情報で裏取りしてください。